SparseOperationKit
Sparse Operation Kit (SOK) is a Python package wrapped GPU accelerated operations dedicated for sparse training / inference cases. It is designed to be compatible with common deep learning (DL) frameworks like TensorFlow.
Most of the algorithm implementations in SOK are extracted from HugeCTR. HugeCTR is a GPU-accelerated recommender framework designed to distribute training across multiple GPUs and nodes for Click-Through Rate (CTR) estimation. If you are looking for a very efficient solution for CTR estimation, please see the HugeCTR documentation or our GitHub repository.
Features
Model-Parallelism GPU Embedding Layer
In sparse training / inference scenarios, for instance, CTR estimation, there are vast amounts of parameters which cannot fit into the memory of a single GPU. Many common DL frameworks only offer limited support for model parallelism (MP), because it can complicate using all available GPUs in a cluster to accelerate the whole training process.
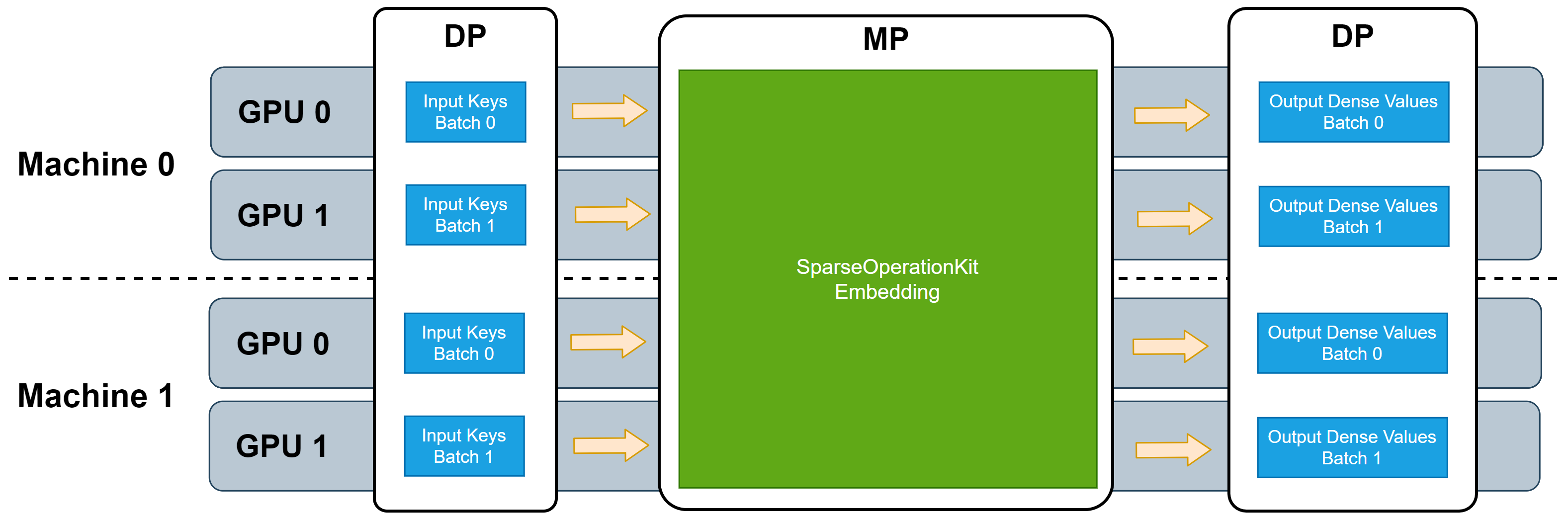
SOK provides broad MP functionality to fully utilize all available GPUs, regardless of whether these GPUs are located in a single machine or multiple machines. Simultaneously, SOK takes advantage of existing data-parallel (DP) capabilities of DL frameworks to accelerate training while minimizing code changes. With SOK embedding layers, you can build a DNN model with mixed MP and DP. MP is used to shard large embedding parameter tables, such that they are distributed among the available GPUs to balance the workload, while DP is used for layers that only consume little GPU resources.
SOK provides multiple types of MP embedding layers, optimized for different application scenarios. These embedding layers can leverage all available GPU memory in your cluster to store/retrieve embedding parameters. As a result, all utilized GPUs work synchronously.
SOK is compatible with DP training provided by common synchronized training frameworks, such as Horovod. Because the input data fed to these embedding layers can take advantage of DP, additional DP from/to MP transformations are needed when SOK is used to scale up your DNN model from single GPU to multiple GPUs. The following picture illustrates the workflow of these embedding layers.
Experiment Features
To provide better flexibility and performance, we are making a major upgrade to SOK. We put the updates under sok.experiment namespace for now, you can import these new functions with the following commands.
from sparse_operation_kit import experiment as sok
With this experimental module, we provide new distributed embedding operations and dynamic variables whose size can grow dynamically. More importantly, they do not need to be used together (although they can be), they can be used separately with native tensorflow.
Note that the components under sok.experiment are not compatible with components outside of sok.experiment. They are all redesigned and in the future, when the components in sok.experiment are stable enough, we will replace other components in SOK with this new version SOK (things under sok.experiment) and deprecate the old version.
You can find the experiment api at API Docs section and find the examples at Examples section.
Installation
There are several ways to install this package.
Obtaining SOK and HugeCTR via Docker
This is the quickest way to get started with SOK. We provide Docker images with pre-compiled binaries of the latest HugeCTR and SOK version. To run it as a docker container in your machine, enter:
docker run nvcr.io/nvidia/merlin/merlin-tensorflow:22.09
Sparse Opeation Kit is already installed, and can be imported directly via:
import sparse_operation_kit as sok
Installing SOK via pip
You can install SOK using the following command:
pip install sparse_operation_kit
Building SOK from source
You can also build the SOK module from souce code. Here are the steps to follow:
Download the source code
$ git clone https://github.com/NVIDIA-Merlin/HugeCTR hugectr
Install to system
$ cd hugectr/sparse_operation_kit/ $ python setup.py install
Documents
Want to find more about SparseOperationKit? Take a look at the SparseOperationKit documentation!