Introduction to HugeCTR
About HugeCTR
HugeCTR is a GPU-accelerated framework designed to distribute training across multiple GPUs and nodes and estimate click-through rates (CTRs). HugeCTR supports model-parallel embedding tables and data-parallel neural networks and their variants such as Wide and Deep Learning (WDL), Deep Cross Network (DCN), DeepFM, and Deep Learning Recommendation Model (DLRM). HugeCTR is a component of NVIDIA Merlin. Merlin is used for building large-scale recommender systems, which require massive datasets to train, particularly for deep learning based solutions.
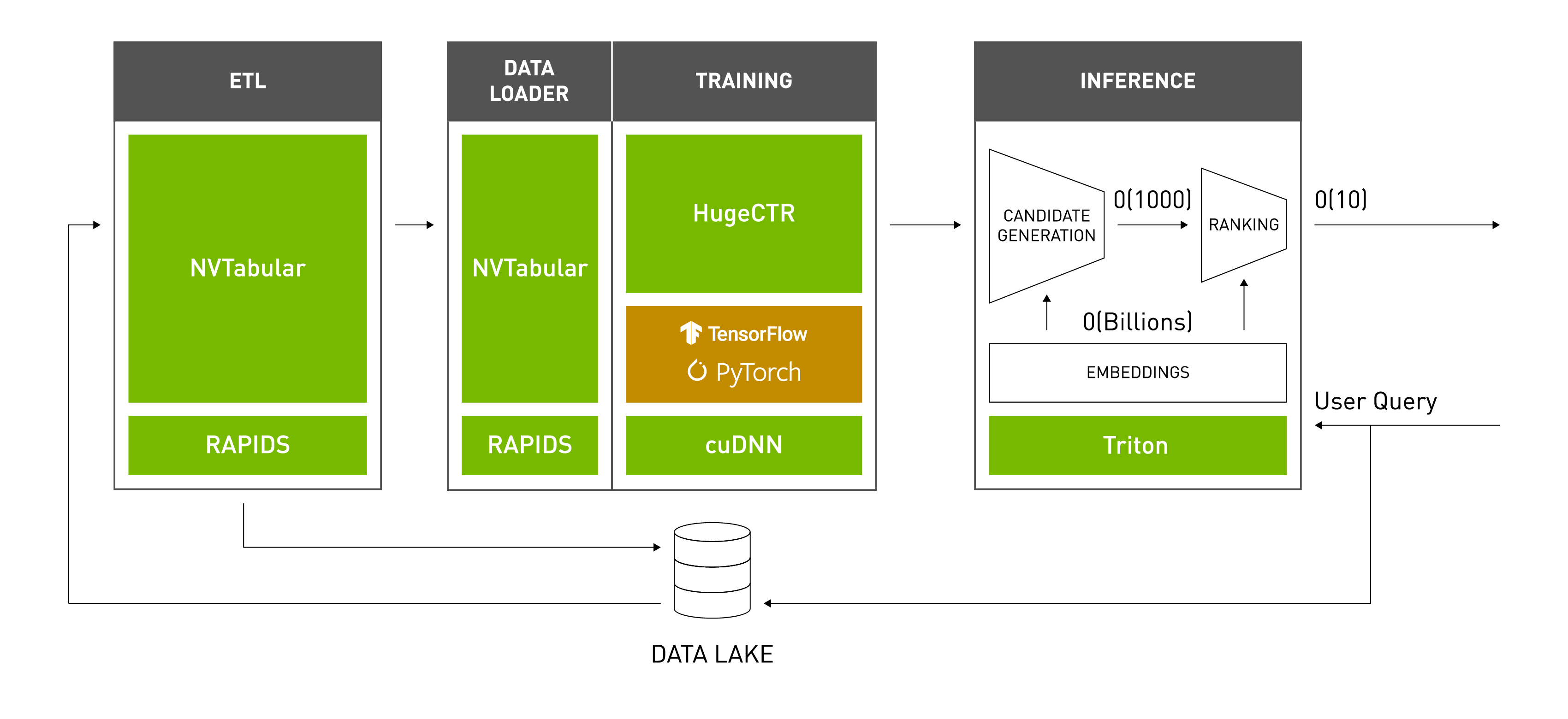
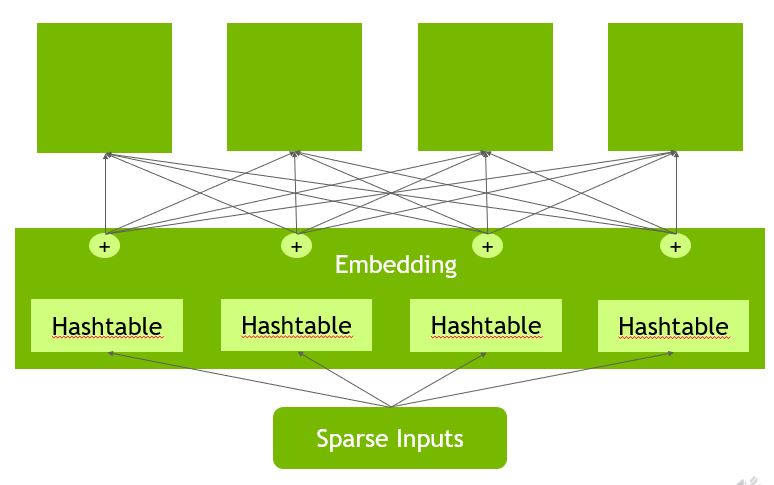
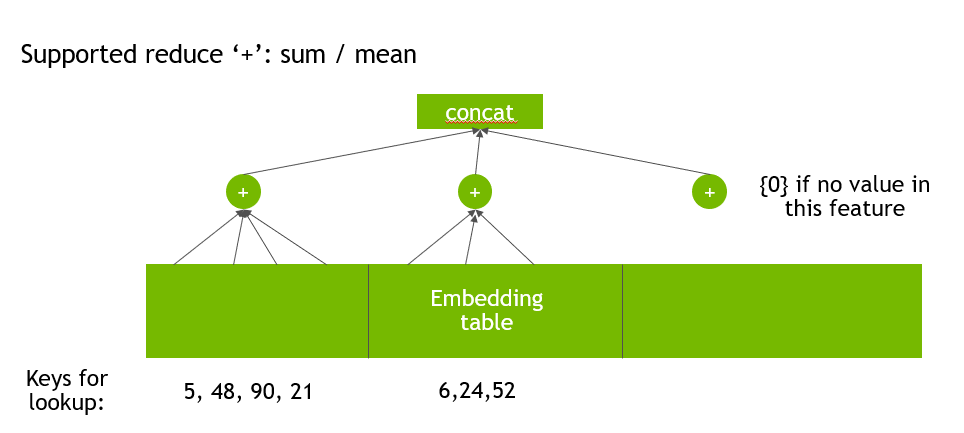
To prevent data loading from becoming a major bottleneck during training, HugeCTR contains a dedicated data reader that is inherently asynchronous and multi-threaded. It will read a batched set of data records in which each record consists of high-dimensional, extremely sparse, or categorical features. Each record can also include dense numerical features, which can be fed directly to the fully connected layers. An embedding layer is used to compress the sparse input features to lower-dimensional, dense embedding vectors. There are three GPU-accelerated embedding stages:
Table lookup
Weight reduction within each slot
Weight concatenation across the slots
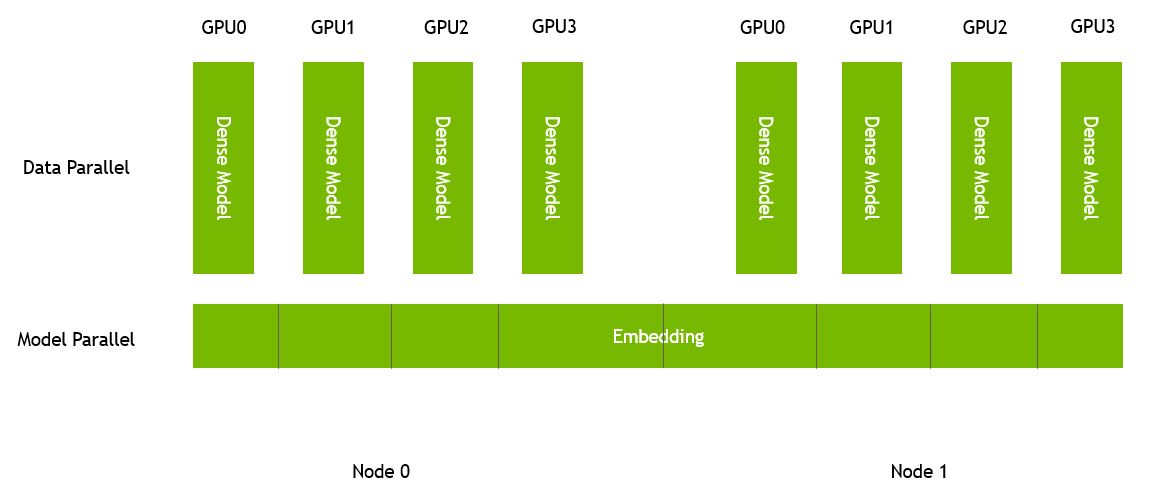
To enable large embedding training, the embedding table in HugeCTR is model parallel and distributed across all GPUs in a homogeneous cluster, which consists of multiple nodes. Each GPU has its own:
feed-forward neural network (data parallelism) to estimate CTRs.
hash table to make the data preprocessing easier and enable dynamic insertion.
Embedding initialization is not required before training takes place since the input training data are hash values (64-bit signed integer type) instead of original indices. A pair of <key,value> (random small weight) will be inserted during runtime only when a new key appears in the training data and the hash table cannot find it.
Installing and Building HugeCTR
You can either install HugeCTR easily using the Merlin Docker image in NGC, or build HugeCTR from scratch using various build options if you’re an advanced user.
Compute Capability
We support the following compute capabilities:
Compute Capability |
GPU |
|
|---|---|---|
6.0 |
NVIDIA P100 (Pascal) |
60 |
7.0 |
NVIDIA V100 (Volta) |
70 |
7.5 |
NVIDIA T4 (Turing) |
75 |
8.0 |
NVIDIA A100 (Ampere) |
80 |
Installing HugeCTR Using NGC Containers
All NVIDIA Merlin components are available as open source projects. However, a more convenient way to utilize these components is by using our Merlin NGC containers. These containers allow you to package your software application, libraries, dependencies, and runtime compilers in a self-contained environment. When installing HugeCTR using NGC containers, the application environment remains portable, consistent, reproducible, and agnostic to the underlying host system’s software configuration.
HugeCTR is included in the Merlin Docker containers that are available from the NVIDIA container repository. You can query the collection for containers that match the HugeCTR label. The following table also identifies the containers:
Container Name |
Container Location |
Functionality |
|---|---|---|
merlin-hugectr |
https://catalog.ngc.nvidia.com/orgs/nvidia/teams/merlin/containers/merlin-hugectr |
NVTabular, HugeCTR, and Triton Inference |
merlin-tensorflow |
https://catalog.ngc.nvidia.com/orgs/nvidia/teams/merlin/containers/merlin-tensorflow |
NVTabular, TensorFlow, and HugeCTR Tensorflow Embedding plugin |
To use these Docker containers, you’ll first need to install the NVIDIA Container Toolkit to provide GPU support for Docker. You can use the NGC links referenced in the table above to obtain more information about how to launch and run these containers.
The following sample command pulls and starts the Merlin Training container:
# Run the container in interactive mode
$ docker run --gpus=all --rm -it --cap-add SYS_NICE nvcr.io/nvidia/merlin/merlin-hugectr:22.12
Building HugeCTR from Scratch
To build HugeCTR from scratch, refer to the contributor guide information.
Tools
We currently support the following tools:
Data Generator: A configurable data generator, which is available from the Python interface, can be used to generate a synthetic dataset for benchmarking and research purposes.
Preprocessing Script: We provide a set of scripts that form a template implementation to demonstrate how complex datasets, such as the original Criteo dataset, can be converted into HugeCTR using supported dataset formats such as Norm and RAW. It’s used in all of our samples to prepare the data and train various recommender models.
Generating Synthetic Data and Benchmarks
The Norm (with Header) and Raw (without Header) datasets can be generated with hugectr.tools.DataGenerator. For categorical features, you can configure the probability distribution to be uniform or power-law within hugectr.tools.DataGeneratorParam. The default distribution is power law with alpha = 1.2.
Generate the
Normdataset for DCN and start training the HugeCTR model:python3 ../tools/data_generator/dcn_norm_generate_train.pyGenerate the
Normdataset for WDL and start training the HugeCTR model:python3 ../tools/data_generator/wdl_norm_generate_train.pyGenerate the
Rawdataset for DLRM and start training the HugeCTR model:python3 ../tools/data_generator/dlrm_raw_generate_train.pyGenerate the
Parquetdataset for DCN and start training the HugeCTR model:python3 ../tools/data_generator/dcn_parquet_generate_train.py
Downloading and Preprocessing Datasets
Download the Criteo 1TB Click Logs dataset using HugeCTR/tools/preprocess.sh and preprocess it to train the DCN. The file_list.txt, file_list_test.txt, and preprocessed data files are available within the criteo_data directory. For more information, refer to the samples directory on GitHub.
For example:
$ cd tools # assume that the downloaded dataset is here
$ bash preprocess.sh 1 criteo_data pandas 1 0