Hierarchical Parameter Server Plugin for TensorRT
Introduction to the HPS Plugin for TensorRT
Hierarchical Parameter Server (HPS) is a distributed inference framework that is dedicated to deploying large embedding tables and realizing the low-latency retrieval of embeddings. The framework combines a high-performance GPU embedding cache with a hierarchical storage architecture that encompasses different types of database backends. The HPS plugin for TensorRT can be integrated into the TensorRT network as a custom layer to build the engine. The TensorRT engine with HPS Plugin for TensorRT can perform low-latency embedding lookup for large tables and accelerated forward propagation for dense network at the same time.
Workflow
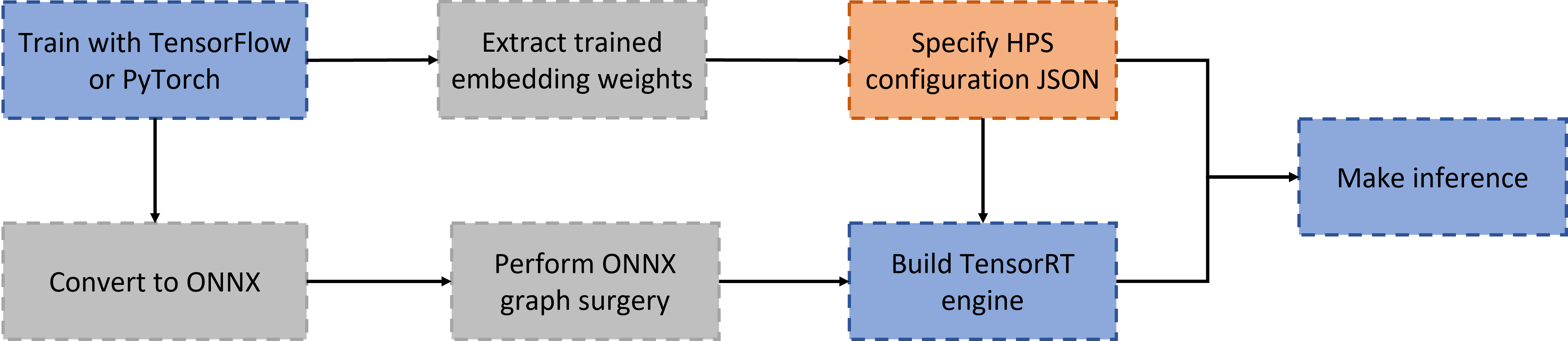
The workflow to leverage the HPS plugin for TensorRT is shown in Fig. 1:
Convert trained models to ONNX: The models trained with different frameworks are converted to ONNX using the popular tools tf2onnx, torch.onnx, hugectr2onnx, and so on.
Perform ONNX graph surgery: The node for embedding lookup in the ONNX graph is replaced by the placeholder of HPS plugin for TensorRT using the tool ONNX GraphSurgeon, as shown in Fig. 2.
Build the TensorRT engine with HPS Plugin for TensorRT: We can build the TensorRT engine based on the modified ONNX graph where the HPS can leveraged as a custom plugin layer.
Deploy the engine on the Triton backend for TensorRT: The TensorRT engine with HPS Plugin for TensorRT is deployed on the Triton backend for TensorRT. Set the
LD_PRELOAD=/usr/local/hps_trt/lib/libhps_plugin.soenvironment variable to load the plugin shared library when you start Triton Inference Server.

Installation
Compute Capability
The plugin supports the following compute capabilities:
Compute Capability |
GPU |
SM |
|---|---|---|
7.0 |
NVIDIA V100 (Volta) |
70 |
7.5 |
NVIDIA T4 (Turing) |
75 |
8.0 |
NVIDIA A100 (Ampere) |
80 |
Installing HPS Using NGC Containers
All NVIDIA Merlin components are available as open source projects. However, a more convenient way to use these components is by using our Merlin NGC containers. These containers allow you to package your software application, libraries, dependencies, and runtime compilers in a self-contained environment. When installing HPS using NGC containers, the application environment remains portable, consistent, reproducible, and agnostic to the underlying host system’s software configuration.
HPS is included in the Merlin Docker containers that are available from the NVIDIA GPU Cloud (NGC) catalog. Access the catalog of containers at https://catalog.ngc.nvidia.com/containers. To use these Docker containers, you must install the NVIDIA Container Toolkit to provide GPU support for Docker.
The following sample commands pull and start the Merlin TensorFlow container, Merlin PyTorch container, or Merlin HugeCTR container:
Merlin TensorFlow
# Run the container in interactive mode
$ docker run --gpus=all --rm -it --cap-add SYS_NICE nvcr.io/nvidia/merlin/merlin-tensorflow:23.02
Merlin PyTorch
# Run the container in interactive mode
$ docker run --gpus=all --rm -it --cap-add SYS_NICE nvcr.io/nvidia/merlin/merlin-pytorch:23.02
Merlin HugeCTR
# Run the container in interactive mode
$ docker run --gpus=all --rm -it --cap-add SYS_NICE nvcr.io/nvidia/merlin/merlin-hugectr:23.02
You can check the existence of the HPS plugin for TensorRT after launching the container by running the following Python statements:
import ctypes
handle = ctypes.CDLL("/usr/local/hps_trt/lib/libhps_plugin.so", mode=ctypes.RTLD_GLOBAL)
Example Notebooks
We provide a collection of examples as Jupyter Notebooks that demonstrate how to build the TensorRT engine with HPS Plugin for TensorRT for models trained with TensorFlow, PyTorch, or HugeCTR.
Benchmark
We benchmark the DLRM TensorRT engine with HPS Plugin for TensorRT in hps_dlrm_benchmark.md.