Performance
Finding ways to enhance HugeCTR’s performance is one of our top priorities. Unlike other frameworks, we apply all the optimizations in the mlperf submission for each release.
We’ve tested HugeCTR’s performance on the following systems:
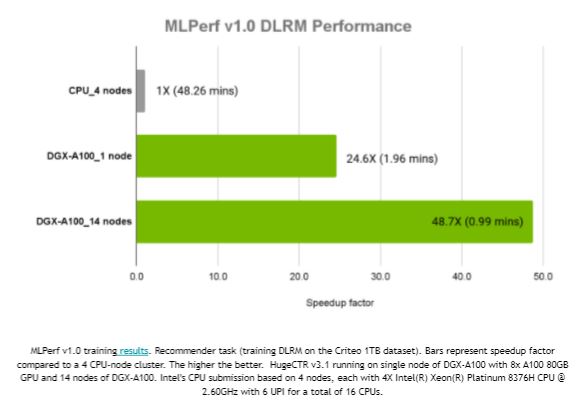
MLPerf on DGX-2 and DGX A100
The DLRM benchmark was submitted to MLPerf Training v0.7 with the release of HugeCTR version 2.2 and MLPerf Training v1.0 with the release of HugeCTR version 3.1. We used the Criteo 1TB Click Logs dataset, which contains 4 billion user and item interactions over 24 days. The DGX-2 with 16 V100 GPUs and DGX A100 with eight A100 GPUs were the target machines. For more information, see this blog post.
Evaluating HugeCTR’s Performance on the DGX-1
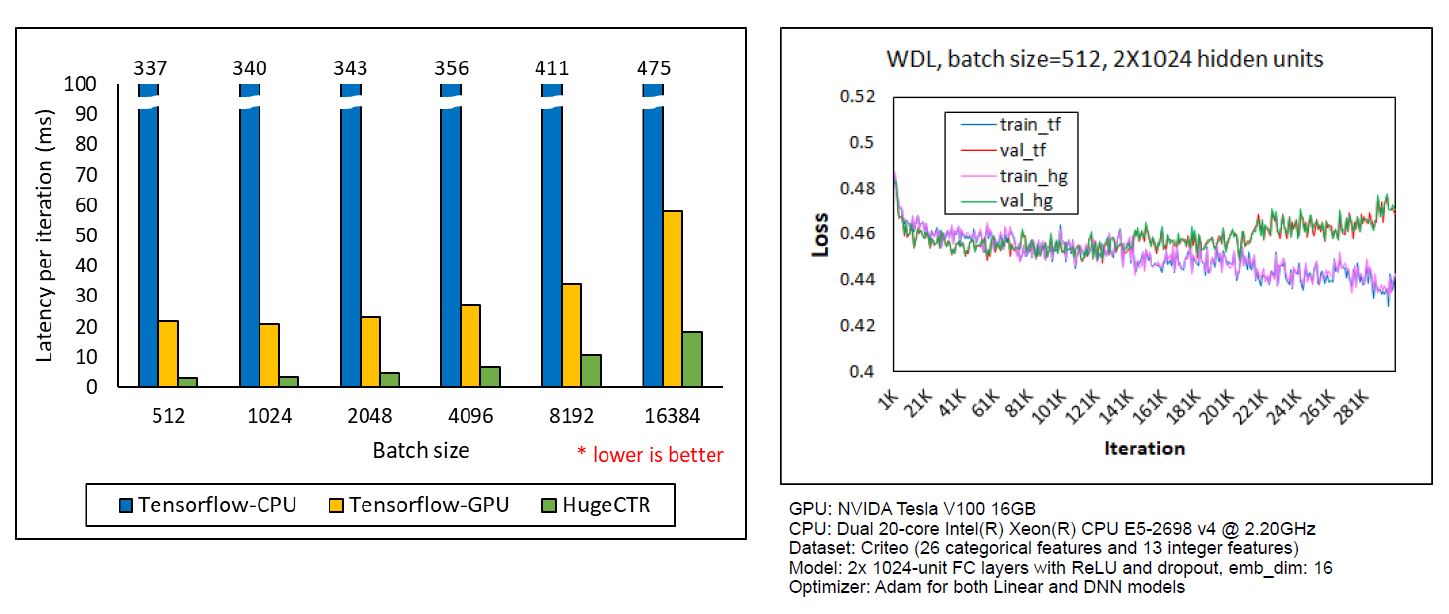
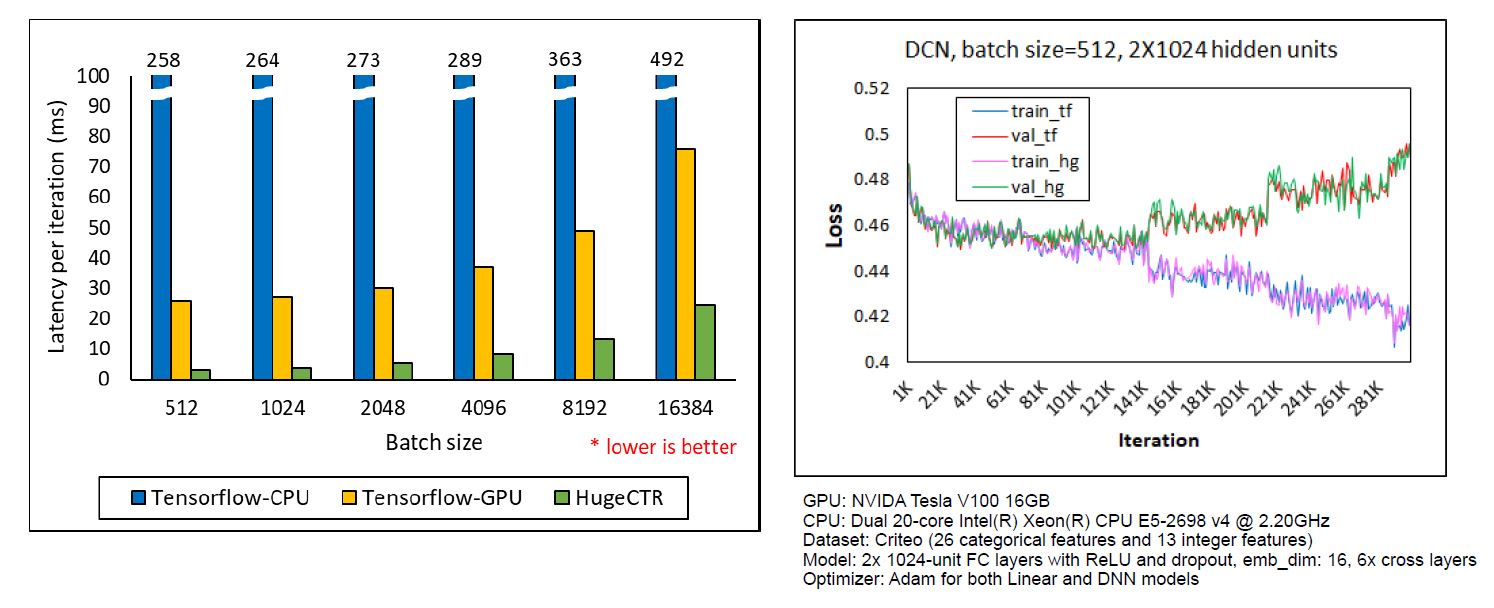
The scalability and performance of HugeCTR has been tested and compared with TensorFlow running on NVIDIA V100 GPUs within a single DGX-1 system. HugeCTR can achieve a speedup that’s 114 times faster than a multi-thread TensorFlow CPU with only one V100 while generating almost the same loss curves for both evaluation and training (see Fig. 2 and Fig. 3).
Test environment:
CPU Server: Dual 20-core Intel® Xeon® CPU E5-2698 v4 @ 2.20GHz
TensorFlow version 2.0.0
V100 16GB: NVIDIA DGX1 servers
Network:
Wide Deep Learning: Nx 1024-unit FC layers with ReLU and dropout, emb_dim: 16; Optimizer: Adam for both Linear and DNN modelsDeep Cross Network: Nx 1024-unit FC layers with ReLU and dropout, emb_dim: 16, 6x cross layers; Optimizer: Adam for both Linear and DNN models
Dataset: The data is provided by CriteoLabs. The original training set contains 45,840,617 examples. Each example contains a label (0 by default OR 1 if the ad was clicked) and 39 features in which 13 are integer and 26 are categorical.
Preprocessing:
Common: Preprocessed by using the scripts available in the tools/criteo_script directory of the GitHub repository.
HugeCTR: Converted to the HugeCTR data format with criteo2hugectr.
TF: Converted to the TFRecord format for efficient training on Tensorflow.
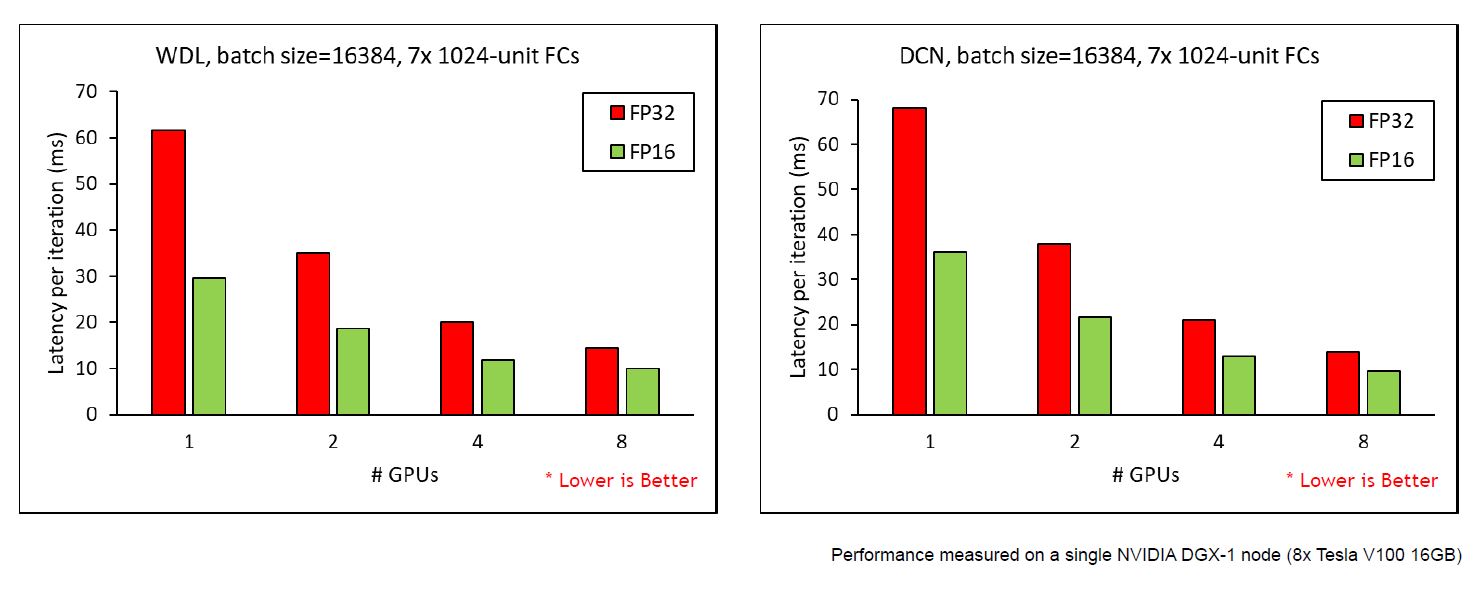
The scalability of HugeCTR and the number of active GPUs have increased simply because of the high-efficient data exchange and three-stage processing pipeline. In this pipeline, we overlap the data reading from the file, host to the device data transaction (inter-node and intra-node), and train the GPU. The following chart shows the scalability of HugeCTR with a batch size of 16384 and seven layers on DGX1 servers.
Evaluating HugeCTR’s Performance on TensorFlow
In the TensorFlow test case that’s shown here, HugeCTR exhibits a speedup up to 114 times faster compared to a CPU server running TensorFlow with only one V100 GPU and almost the same loss curve.