# Copyright 2021 NVIDIA Corporation. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ================================
Deploying a Multi-Stage RecSys into Production with Merlin Systems and Triton Inference Server
This notebook is created using the latest stable merlin-tensorflow-inference container.
At this point, when you reach out to this notebook, we expect that you have already executed the first notebook 01-Building-Recommender-Systems-with-Merlin.ipynb and exported all the required files and models.
We are going to generate recommended items for a given user query (user_id) by following the steps described in the figure below.
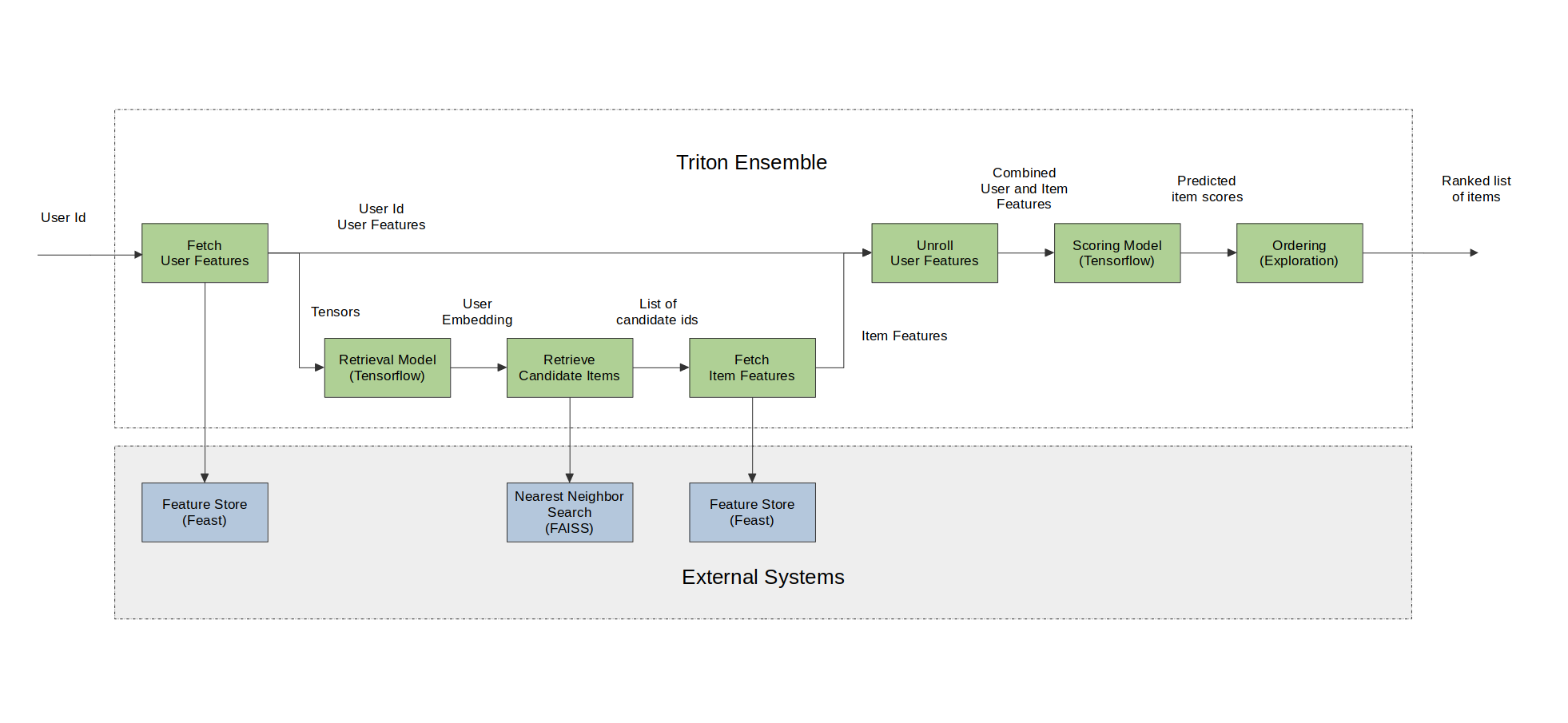
Merlin Systems library have the set of operators to be able to serve multi-stage recommender systems built with Tensorflow on Triton Inference Server(TIS) easily and efficiently. Below, we will go through these operators and demonstrate their usage in serving a multi-stage system on Triton.
Import required libraries and functions
At this step, we assume you already installed the tensorflow-gpu (or -cpu), feast and faiss-gpu (or -cpu) libraries when running the first notebook 01-Building-Recommender-Systems-with-Merlin.ipynb.
In case you need to install them for running this example on GPU, execute the following script in a cell.
%pip install tensorflow "feast<0.20" faiss-gpu
or the following script in a cell for CPU.
%pip install tensorflow-cpu "feast<0.20" faiss-cpu
import os
import numpy as np
import pandas as pd
import feast
import faiss
import seedir as sd
from nvtabular import ColumnSchema, Schema
from merlin.systems.dag.ensemble import Ensemble
from merlin.systems.dag.ops.session_filter import FilterCandidates
from merlin.systems.dag.ops.softmax_sampling import SoftmaxSampling
from merlin.systems.dag.ops.tensorflow import PredictTensorflow
from merlin.systems.dag.ops.unroll_features import UnrollFeatures
from merlin.systems.triton.utils import send_triton_request
Register our features on feature store
The Feast feature registry is a central catalog of all the feature definitions and their related metadata(read more here). We have defined our user and item features definitions in the user_features.py and item_features.py files. With FeatureView() users can register data sources in their organizations into Feast, and then use those data sources for both training and online inference. In the user_features.py and item_features.py files, we are telling Feast where to find user and item features.
Before we move on to the next steps, we need to perform feast applycommand as directed below. With that, we register our features, we can apply the changes to create our feature registry and store all entity and feature view definitions in a local SQLite online store called online_store.db.
BASE_DIR = os.environ.get("BASE_DIR", "/Merlin/examples/Building-and-deploying-multi-stage-RecSys/")
# define feature repo path
feast_repo_path = os.path.join(BASE_DIR, "feature_repo/")
%cd $feast_repo_path
!feast apply
/Merlin/examples/Building-and-deploying-multi-stage-RecSys/feature_repo
/usr/local/lib/python3.8/dist-packages/feast/feature_view.py:100: DeprecationWarning: The argument 'input' is being deprecated. Please use 'batch_source' instead. Feast 0.13 and onwards will not support the argument 'input'.
warnings.warn(
Created entity item_id
Created entity user_id_raw
Created feature view item_features
Created feature view user_features
Created sqlite table feature_repo_item_features
Created sqlite table feature_repo_user_features
Loading features from offline store into an online store
After we execute apply and registered our features and created our online local store, now we need to perform materialization operation. This is done to keep our online store up to date and get it ready for prediction. For that we need to run a job that loads feature data from our feature view sources into our online store. As we add new features to our offline stores, we can continuously materialize them to keep our online store up to date by finding the latest feature values for each user.
When you run the feast materialize .. command below, you will see a message Materializing 2 feature views from 1995-01-01 01:01:01+00:00 to 2025-01-01 01:01:01+00:00 into the sqlite online store will be printed out.
Note that materialization step takes some time…
!feast materialize 1995-01-01T01:01:01 2025-01-01T01:01:01
Materializing 2 feature views from 1995-01-01 01:01:01+00:00 to 2025-01-01 01:01:01+00:00 into the sqlite online store.
item_features:
100%|███████████████████████████████████████████████████████████| 437/437 [00:00<00:00, 3870.31it/s]
user_features:
100%|███████████████████████████████████████████████████████████| 442/442 [00:00<00:00, 1423.30it/s]
Now, let’s check our feature_repo structure again after we ran apply and materialize commands.
# set up the base dir to for feature store
feature_repo_path = os.path.join(BASE_DIR, 'feature_repo')
sd.seedir(feature_repo_path, style='lines', itemlimit=10, depthlimit=5, exclude_folders=['.ipynb_checkpoints', '__pycache__'], sort=True)
feature_repo/
├─__init__.py
├─data/
│ ├─item_features.parquet
│ ├─online_store.db
│ ├─registry.db
│ └─user_features.parquet
├─feature_store.yaml
├─item_features.py
└─user_features.py
Set up Faiss index, create feature store client and objects for the Triton ensemble
Create a folder for faiss index path
if not os.path.isdir(os.path.join(BASE_DIR, 'faiss_index')):
os.makedirs(os.path.join(BASE_DIR, 'faiss_index'))
Define paths for ranking model, retrieval model, and faiss index path
faiss_index_path = os.path.join(BASE_DIR, 'faiss_index', "index.faiss")
retrieval_model_path = os.path.join(BASE_DIR, "query_tower/")
ranking_model_path = os.path.join(BASE_DIR, "dlrm/")
QueryFaiss operator creates an interface between a FAISS Approximate Nearest Neighbors (ANN) Index and Triton Inference Server. For a given input query vector, we do an ANN search query to find the ids of top-k nearby nodes in the index.
setup_faiss is a utility function that will create a Faiss index from an embedding vector with using L2 distance.
from merlin.systems.dag.ops.faiss import QueryFaiss, setup_faiss
item_embeddings = np.ascontiguousarray(
pd.read_parquet(os.path.join(BASE_DIR, "item_embeddings.parquet")).to_numpy()
)
setup_faiss(item_embeddings, faiss_index_path)
WARNING clustering 437 points to 32 centroids: please provide at least 1248 training points
Create feature store client.
feature_store = feast.FeatureStore(feast_repo_path)
Fetch user features with QueryFeast operator from the feature store. QueryFeast operator is responsible for ensuring that our feast feature store can communicate correctly with tritonserver for the ensemble feast feature look ups.
from merlin.systems.dag.ops.feast import QueryFeast
user_features = ["user_id_raw"] >> QueryFeast.from_feature_view(
store=feature_store,
view="user_features",
column="user_id_raw",
include_id=False,
)
Retrieve top-K candidate items using retrieval model that are relevant for a given user. We use PredictTensorflow() operator that takes a tensorflow model and packages it correctly for TIS to run with the tensorflow backend.
# prevent TF to claim all GPU memory
from merlin.models.loader.tf_utils import configure_tensorflow
configure_tensorflow()
<function tensorflow.python.dlpack.dlpack.from_dlpack(dlcapsule)>
topk_retrieval = int(
os.environ.get("topk_retrieval", "100")
)
retrieval = (
user_features
>> PredictTensorflow(retrieval_model_path)
>> QueryFaiss(faiss_index_path, topk=topk_retrieval)
)
2022-09-14 15:28:46.303447: I tensorflow/core/platform/cpu_feature_guard.cc:194] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: SSE3 SSE4.1 SSE4.2 AVX
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2022-09-14 15:28:47.443330: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1532] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 16249 MB memory: -> device: 0, name: Quadro GV100, pci bus id: 0000:2d:00.0, compute capability: 7.0
09/14/2022 03:28:49 PM WARNING:No training configuration found in save file, so the model was *not* compiled. Compile it manually.
Fetch item features for the candidate items that are retrieved from the retrieval step above from the feature store.
item_features = retrieval["candidate_ids"] >> QueryFeast.from_feature_view(
store=feature_store,
view="item_features",
column="candidate_ids",
output_prefix="item",
include_id=True,
)
Merge the user features and items features to create the all set of combined features that were used in model training using UnrollFeatures operator which takes a target column and joins the “unroll” columns to the target. This helps when broadcasting a series of user features to a set of items.
user_features_to_unroll = [
"user_id",
"user_shops",
"user_profile",
"user_group",
"user_gender",
"user_age",
"user_consumption_2",
"user_is_occupied",
"user_geography",
"user_intentions",
"user_brands",
"user_categories",
]
combined_features = item_features >> UnrollFeatures(
"item_id", user_features[user_features_to_unroll]
)
Rank the combined features using the trained ranking model, which is a DLRM model for this example. We feed the path of the ranking model to PredictTensorflow() operator.
ranking = combined_features >> PredictTensorflow(ranking_model_path)
For the ordering we use SoftmaxSampling() operator. This operator sorts all inputs in descending order given the input ids and prediction introducing some randomization into the ordering by sampling items from the softmax of the predicted relevance scores, and finally returns top-k ordered items.
top_k=10
ordering = combined_features["item_id_raw"] >> SoftmaxSampling(
relevance_col=ranking["click/binary_classification_task"], topk=top_k, temperature=20.0
)
Export Graph as Ensemble
The last step is to create the ensemble artifacts that TIS can consume. To make these artifacts import the Ensemble class. This class represents an entire ensemble consisting of multiple models that run sequentially in TIS initiated by an inference request. It is responsible with interpreting the graph and exporting the correct files for TIS.
When we create an Ensemble object we feed the graph and a schema representing the starting input of the graph. After we create the ensemble object, we export the graph, supplying an export path for the ensemble.export() function. This returns an ensemble config which represents the entire inference pipeline and a list of node-specific configs.
Create the folder to export the models and config files.
if not os.path.isdir(os.path.join(BASE_DIR, 'poc_ensemble')):
os.makedirs(os.path.join(BASE_DIR, 'poc_ensemble'))
Create a request schema that we are going to use when sending a request to Triton Inference Server (TIS).
request_schema = Schema(
[
ColumnSchema("user_id_raw", dtype=np.int32),
]
)
# define the path where all the models and config files exported to
export_path = os.path.join(BASE_DIR, 'poc_ensemble')
ensemble = Ensemble(ordering, request_schema)
ens_config, node_configs = ensemble.export(export_path)
# return the output column name
outputs = ensemble.graph.output_schema.column_names
print(outputs)
['ordered_ids']
Let’s check our export_path structure
sd.seedir(export_path, style='lines', itemlimit=10, depthlimit=5, exclude_folders=['.ipynb_checkpoints', '__pycache__'], sort=True)
poc_ensemble/
├─0_queryfeast/
│ ├─1/
│ │ └─model.py
│ └─config.pbtxt
├─1_predicttensorflow/
│ ├─1/
│ │ └─model.savedmodel/
│ │ ├─assets/
│ │ ├─keras_metadata.pb
│ │ ├─saved_model.pb
│ │ └─variables/
│ │ ├─variables.data-00000-of-00001
│ │ └─variables.index
│ └─config.pbtxt
├─2_queryfaiss/
│ ├─1/
│ │ ├─index.faiss/
│ │ │ └─index.faiss
│ │ └─model.py
│ └─config.pbtxt
├─3_queryfeast/
│ ├─1/
│ │ └─model.py
│ └─config.pbtxt
├─4_unrollfeatures/
│ ├─1/
│ │ └─model.py
│ └─config.pbtxt
├─5_predicttensorflow/
│ ├─1/
│ │ └─model.savedmodel/
│ │ ├─assets/
│ │ ├─keras_metadata.pb
│ │ ├─saved_model.pb
│ │ └─variables/
│ │ ├─variables.data-00000-of-00001
│ │ └─variables.index
│ └─config.pbtxt
├─6_softmaxsampling/
│ ├─1/
│ │ └─model.py
│ └─config.pbtxt
└─ensemble_model/
├─1/
└─config.pbtxt
Starting Triton Server
It is time to deploy all the models as an ensemble model to Triton Inference Serve TIS. After we export the ensemble, we are ready to start the TIS. You can start triton server by using the following command on your terminal:
tritonserver --model-repository=/ensemble_export_path/ --backend-config=tensorflow,version=2
For the --model-repository argument, specify the same path as the export_path that you specified previously in the ensemble.export method. This command will launch the server and load all the models to the server. Once all the models are loaded successfully, you should see READY status printed out in the terminal for each loaded model.
Retrieving Recommendations from Triton
Once our models are successfully loaded to the TIS, we can now easily send a request to TIS and get a response for our query with send_triton_request utility function.
Let’s send a request to TIS for a given user_id_raw value.
# read in data for request
from merlin.core.dispatch import make_df
# create a request to be sent to TIS
request = make_df({"user_id_raw": [7]})
request["user_id_raw"] = request["user_id_raw"].astype(np.int32)
print(request)
user_id_raw
0 7
Let’s return raw item ids from TIS as top-k recommended items per given request.
response = send_triton_request(request_schema, request, outputs)
response
{'ordered_ids': array([[117],
[415],
[228],
[985],
[ 76],
[410],
[193],
[120],
[ 87],
[139]], dtype=int32)}
That’s it! You finished deploying a multi-stage Recommender Systems on Triton Inference Server using Merlin framework.