Model Architectures
Modular Building-Block Design
Transformers4Rec provides modularized building blocks that you can combine with standard PyTorch modules. This provides a great flexibility in the model definition so that you can use these blocks to build custom architectures with multiple towers, multiple heads, and losses (multi-task). For more information about the available options for each building block, refer to our API Documentation.
The following figure shows a reference architecture for next-item prediction with Transformers. The model can be used for both sequential and session-based recommendation. This architecture can be divided into four conceptual layers:
Feature aggregation (Input Block)
Sequence masking
Sequence processing (Transformer/RNN Block)
Prediction head (Output Block)
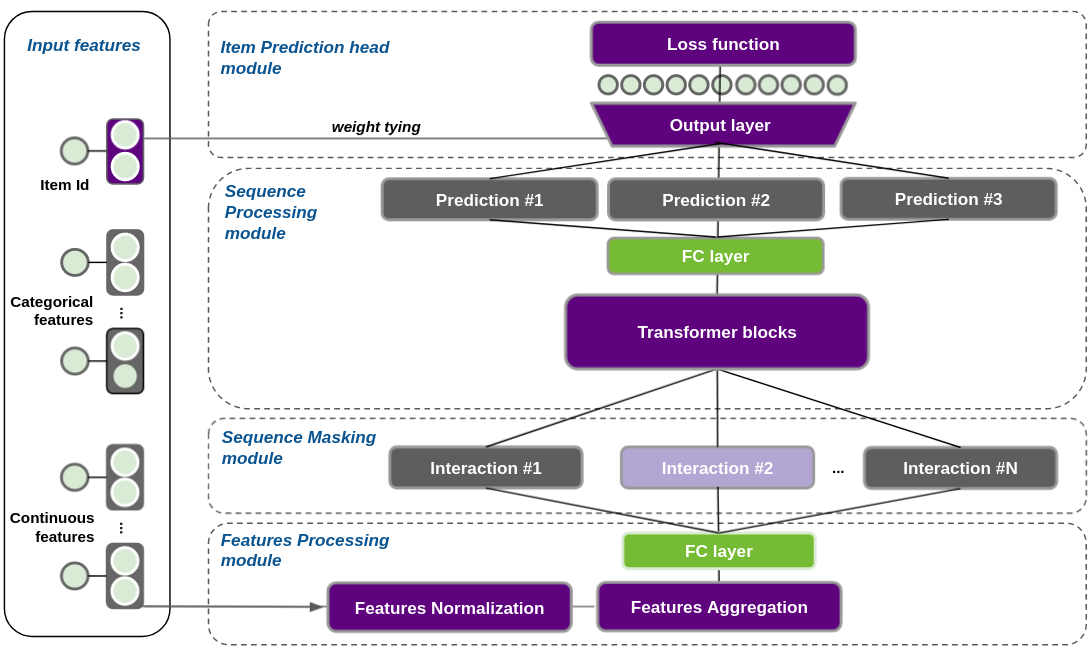
Feature Aggregation (Input Block)
To read the sequences of input features like user IDs, user metadata, item IDs, and item metadata into a Transformer block, the sequences must be aggregated into a single vector representation per element in the sequence that we call the interaction embedding.
The following list identifies the aggregation methods:
Concat: Concatenation of the features.
Element-wise sum: Features are summed in which all features must have the same dimension. For example, categorical embeddings must have the same dimension and continuous features are projected to that dimension.
Element-wise sum with item multiplication: Similar to the Element-wise sum aggregation in which all features are summed except for the item ID embedding because it is multiplied by the other features’ sum. The aggregation formula is available in our Transformers4Rec: Bridging the Gap between NLP and Sequential / Session-Based Recommendation paper.
Categorical features are represented by embeddings. Numerical features can be represented as a scalar and projected by a fully-connected (FC) layer to multiple dimensions or represented as a weighted average of embeddings by using the soft one-hot encoding technique. For more information, refer to the online appendix to the preceding paper. Categorical input features are optionally normalized (with layer normalization) before aggregation. Continuous features should be normalized during feature engineering of the dataset.
TabularSequenceFeatures is the core class of this module.
This class processes and aggregates all features and outputs a sequence of interaction embeddings to be fed into transformer blocks.
You can create an instance of TabularSequenceFeatures automatically from a dataset schema that is generated from NVTabular by using the from_schema() method.
This method creates the layers that are required to represent the categorical and continuous features in the dataset.
In addition, you can specify the aggregation option of this method to aggregate the sequential features and to prepare masked labels according to the specified sequence masking approach.
The following code block shows one way the TabularSequenceFeatures.from_schema() method can create the interaction embeddings that are ready for use with Transformer blocks:
from transformers4rec.torch import TabularSequenceFeatures
tabular_inputs = TabularSequenceFeatures.from_schema(
schema,
embedding_dim_default=128,
max_sequence_length=20,
d_output=100,
aggregation="concat",
masking="clm"
)
The
embedding_dim_defaultargument sets a fixed dimension for all categorical input features. For more information, see theTabularSequenceFeaturesclass documentation.
Sequence Masking
You can train Transformer architectures in different ways. Depending on the training method, there is a specific masking schema. The masking schema sets the items to be predicted–labels–and masks some positions of the sequence that cannot be used by the Transformer layers for prediction.
Transformers4Rec supports the following training approaches that are inspired by NLP:
Causal Language Modeling (
masking="clm"): Predicts the next item based on past positions of the sequence. Future positions are masked.Masked Language Modeling (
masking="mlm"): Randomly selects some positions of the sequence to predict, which are masked. The Transformer layer is allowed to use positions on the right–future information–during training. During inference, all past items are visible for the Transformer layer as it tries to predict the next item.Permutation Language Modeling (
masking="plm"): Uses a permutation factorization at the level of the self-attention layer to define the accessible bi-directional context.
NOTE: Not all transformer architectures support all of these training approaches. Transformers4Rec raises an exception if you attempt to use an invalid combination and provides suggestions for using the appropriate masking techniques for that architecture.
Sequence Processing (Transformer/RNN Block)
The Transformer block processes the input sequences of interaction embeddings created by the input block using Transformer architectures like XLNet, GPT-2, and so on–or RNN architectures like LSTM or GRU. The created block is a standard Torch block and is compatible with and substitutable by other Torch blocks that support the input of a sequence.
In the following example, a SequentialBlock module is used to build the model body.
The model contains a TabularSequenceFeatures object (tabular_inputs defined in the previous code snippet), followed by an MLP projection layer to 64 dim (to match the Transformer d_model), and then is followed by an XLNet transformer block with two layers (four heads each).
from transformers4rec.config import transformer
from transformers4rec.torch import MLPBlock, SequentialBlock, TransformerBlock
# Configures the XLNet Transformer architecture.
transformer_config = transformer.XLNetConfig.build(
d_model=64, n_head=4, n_layer=2, total_seq_length=20
)
# Defines the model body including: inputs, masking, projection and transformer block.
model_body = SequentialBlock(
tabular_inputs,
torch4rec.MLPBlock([64]),
torch4rec.TransformerBlock(transformer_config, masking=tabular_inputs.masking)
)
Prediction Head (Output Block)
Following the input and transformer blocks, the model outputs its predictions. Transformers4Rec supports the following prediction heads, which can have multiple losses and can be combined for multi-task learning and multiple metrics:
Next Item Prediction: Predicts next items for a given sequence of interactions. During training, the prediction can be the next item or randomly selected items depending on the masking scheme. For inference, the intended purpose is to always predict the next interacted item. Cross-entropy and pairwise losses are supported.
Binary Classification: Predicts a binary feature using the whole sequence. In the context of recommendation, you can use classification to predict the user’s next action such as whether the user will abandon a product in their cart or proceed with the purchase.
Regression: Predicts a continuous feature using the whole sequence, such as the elapsed time until the user returns to a service.
In the following example, a head is instantiated with the predefined model_body for the NextItemPredictionTask.
This head enables the weight_tying option.
Decoupling the model bodies and heads provides a flexible architecture that enables you to define a model with features like multiple towers and multiple heads.
Lastly, the Model class combines the heads and wraps the whole model.
from transformers4rec.torch import Head, Model
from transformers4rec.torch.model.head import NextItemPredictionTask
# Defines the head related to next item prediction task
head = Head(
model_body,
NextItemPredictionTask(weight_tying=True),
inputs=inputs,
)
# Get the end-to-end Model class
model = Model(head)
Tying Embeddings
For the NextItemPredictionTask class, we recommend tying embeddings.
The tying embeddings concept was initially proposed by the NLP community to tie the weights of the input (item ID) embedding matrix with the output projection layer.
Not only do tied embeddings reduce the memory requirements significantly, but our own experimentation during recent competitions and empirical analysis detailed in our Transformers4Rec: Bridging the Gap between NLP and Sequential / Session-Based Recommendation paper and online appendix demonstrate that this method is very effective.
Tying embeddings is enabled by default, but can be disabled by setting weight_tying to False.
Regularization
Transformers4Rec supports a number of regularization techniques such as dropout, weight decay, softmax temperature scaling, stochastic shared embeddings, and label smoothing. In our extensive experimentation, we hypertuned all regularization techniques for different datasets and found out that label smoothing was particularly useful at improving both training and validation accuracy and better at calibrating the predictions.