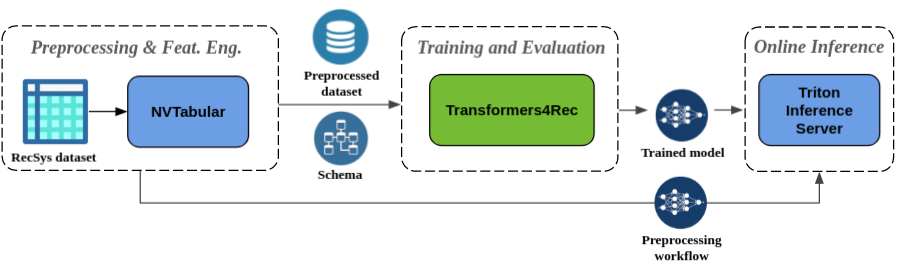
End-to-End Pipeline with Hugging Face Transformers and NVIDIA Merlin
Overview of the Pipeline
Transformers4Rec has a first-class integration with Hugging Face (HF) Transformers, NVTabular, and Triton Inference Server, making it easy to build end-to-end GPU accelerated pipelines for sequential and session-based recommendation.
Integration with Hugging Face Transformers
Transformers4Rec integrates with Hugging Face Transformers, allowing RecSys researchers and practitioners to easily experiment with the latest state-of-the-art NLP Transformer architectures for sequential and session-based recommendation tasks and deploy those models into production.
HF Transformers has become very popular among NLP researchers and practitioners (more than 900 contributors), providing standardized implementations of the state-of-the-art transformer architectures (more than 68 and counting) produced by the research community, often within days or weeks of their publication.
Models are composed of three building blocks:
Tokenizer that converts raw text to sparse index encodings
Transformer architecture
Head for NLP tasks such as text classification, generation, sentiment analysis, translation, and summarization
Only the Transformer architecture building block and their configuration classes are leveraged from HF Transformers.
Transformers4Rec provides additional building blocks that are necessary for recommendation such as input features like normalization and aggregation as well as heads for recommendation and sequence classification and prediction.
These building blocks’ Trainer class are extended to enable evaluation with RecSys metrics.
Integration with NVTabular
NVTabular is a feature engineering and preprocessing library for tabular data that is designed to easily manipulate datasets at terabyte scale and train deep learning (DL) based recommender systems.
Some popular techniques have been implemented within NVTabular to deal with categorical and numerical features, such as Categorify, Normalize, Bucketize, TargetEncoding, and DifferenceLag, and allow for custom transformations (LambdaOp) to be defined using cuDF data frame operations.
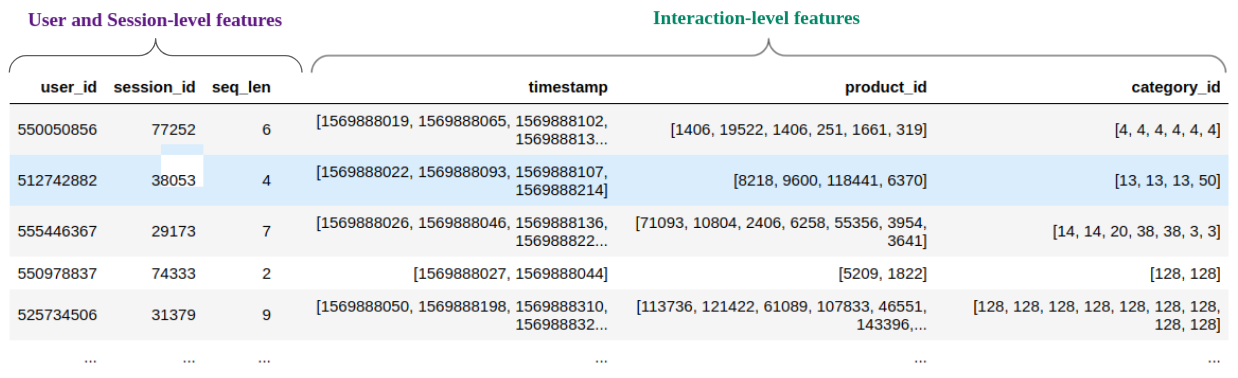
Typically, the input RecSys datasets contain one example per user interaction. For sequential recommendation, the training example is a sequence of user interactions. For session-based recommendation, the training example is a sequence of session interactions. In practice, each interaction-level feature needs to be converted to a sequence that is grouped by user or session and their sequence length must match since each position of the sequence corresponds to one interaction.
The following figure provides a visualization of the preprocessed tabular data:
NVTabular can easily prepare such data with the Groupby operation.
This operation supports grouping by a categorical column such as user ID and session ID, sorting by another column such as timestamp and aggregating other columns as sequences (list), or by taking the first or last element of the sequence as shown in the following code block.
groupby_features = [
'user_id', 'session_id', 'product_id', 'category_id', 'timestamp'
] >> ops.Groupby(
groupby_cols=['session_id'],
sort_cols=['timestamp'],
aggs={
'product_id': 'list',
'category_id': 'list',
'timestamp': ['first', 'last'],
},
)
Outputs
NVTabular can save preprocessed data in the Parquet file format. You can partition the data by a categorical column, such as day and company, as shown in the following example:
nvt_output_path ='./output'
partition_col = ['day']
nvt.Dataset(dataset).to_parquet(nvt_output_path, partition_on=[partition_col])
NVTabular also creates a schema file, schema.pbtxt, in the protobuf text format with the Parquet files.
The schema file contains statistics that are obtained during the preprocessing such as the cardinality of categorical features and the maximum sequence length for sequential features.
NVTabular also supports the association of tags for features.
You can use the tags to indicate the item ID, item and user features, and categorical or continuous features.
This example of a schema.pbtxt file properly formats the schema in protobuf text.
NOTE: If you don’t use NVTabular to preprocess your data, you can also instantiate a Schema in code manually as shown in this schema example Python program.
After you call workflow.fit(), you can save the workflow so that you can apply the same preprocessing workflow to new input data as a batch or online by using the Triton Inference Server integration.
The following code block shows how to save an NVTabular workflow:
# Instantiates an NVTabular dataset
dataset = nvt.Dataset([os.path.join(INPUT_PATH, "*.parquet")], part_size="100MB")
# Perform a single pass over the dataset to collect columns statistics
workflow.fit(dataset)
# Applies the transform ops to the dataset
new_dataset = workflow.transform(dataset)
# Saves the preprocessed dataset in parquet files
new_dataset.to_parquet("/path")
# Saves the "fitted" preprocessing workflow
workflow.save(os.path.join(OUTPUT_PATH, "workflow"))
Integration with Triton Inference Server
NVIDIA Triton Inference Server (TIS) simplifies the deployment of AI models at scale to production. TIS is a cloud and edge inferencing solution that is optimized to deploy machine learning models for GPUs and CPUs. It supports a number of different deep learning frameworks such as TensorFlow and PyTorch.
An end-to-end ML/DL pipeline consists of preprocessing and feature engineering (ETL), model training, and model deployment for inference. Model deployment to production is the critical step of this pipeline because it enables model inference for practical business decisions. In the production setting, we want to apply the input data to the same data transformation operations that were completed during training (ETL). Essentially, the preprocessing operations, such as standardizing continuous features and encoding categorical features, should be compatible with the statistics of the original data before feeding data to the deep learning model. NVTabular supports the same scenario when you save the data processing workflow along with a trained PyTorch or Tensorflow model in a single ensemble pipeline to be served on TIS.
The TIS integration enables the deployment of deep learning recommender models at scale with GPU acceleration. Transformers4Rec supports exporting a model trained with the PyTorch API to Triton Inference Server using the Python backend.
To learn about how to deploy a large and complex recommender workflow to production with only a few lines of code, refer to our end-to-end-session-based recommendation notebook and session-based recommendation on GPU with Transformers4Rec notebook.