Multi-GPU data-parallel training using the Trainer class
To train models faster, users can use Data-Parallel training when using transformers4rec.Trainer for training. Data-parallel multi-GPU training distributes train data between GPUs to speedup training and support larger batch sizes at each step.
The Trainer class supports both DataParallel and DistributedDataParallel built-in features of PyTorch. Here we explain how each of these training modes can be used in Transformers4Rec.
DataParallel
When the DataParallel mode is used, the following happens for each training step:
GPU-0 reads a batch then evenly distributes it among available GPUs
The latest model will be copied to all GPUs
A Python thread is created for each GPU to run
forward()step and the partial loss will be sent to GPU-0 to compute the global lossComputed global loss is broadcasted to all GPU threads to run
backward()Gradients from each GPU are sent to GPU-0 and their average is computed
As we see, parallelism in DataParallel mode is implemented through Python threads which will be blocked by GIL (Global Interepreter Lock) so DataParallel is not the preferred method. Users are advised to use DistributedDataParallel instead as it uses multi-processing and is better maintained. Also, some model types such as transfoxl can not be used with DataParallel. To learn more about DataParallel refer to PyTorch documentation.
To use the DataParallel mode training, user just needs to make sure CUDA_VISIBLE_DEVICES is set. For example when 2 GPUs are available:
Add
os.environ["CUDA_VISIBLE_DEVICES"]="0,1"to the script
or
Run
export CUDA_VISIBLE_DEVICES=0,1in the terminal
Do not try wrapping the model with torch.nn.DataParallel yourself because that will break automatic wrapping done by Trainer.
Note: When using DataParallel the dataloader generates one batch on each train step then the batch will be divided between GPUs so the per_device_train_batch_size argument represents the total batch size in this mode, not size of the batch each GPU receives.
DistributedDataParallel
This is the suggested and more efficient method. When a model is trained using the DistributedDataParallel mode:
A separate process will be assigned to each GPU in the beginning and GPU-0 will replicate the model on each GPU
On each step each GPU receives a different mini-batch produced by the dataloader
On the backward pass the gradient from GPUs will be averaged for accumulation
To learn more about DistributedDataParallel see the PyTorch Documentation.
To train using the DistributedDataParallel mode user should use PyTorch distributed launcher to run the script:
python -m torch.distributed.launch --nproc_per_node N_GPU your_script.py --your_arguments
To have one process per GPU, replace N_GPU with the number of GPUs you want to use. Optionally, you can also set CUDA_VISIBLE_DEVICES accordingly.
Note: When using DistributedDataParallel, our data loader splits data between the GPUs based on dataset partitions. For that reason, the number of partitions of the dataset must be equal to or an integer multiple of the number of processes. If the parquet file has a small number of row groups (partitions), try repartitioning and saving it again using cudf or pandas before training. The dataloader checks dataloader.dataset.npartitions and will repartition if needed but we advise users to repartition the dataset and save it for better efficiency. Use pandas or cudf for repartitioning. Example of repartitioning a parquet file with cudf:
gdf.to_parquet("filename.parquet", row_group_size_rows=10000)
Choose row_group_size_rows such that nr_rows/row_group_size_rows>=n_proc because n_rows=npartition*row_group_size_rows.
With pandas, use the argument as row_group_size=10000 instead.
Please make sure that the resulting number of partitions is divisible by number of GPUs to be used (eg. 2 or 4 partitions, if 2 GPUs will be used).
Performance Comparison
We trained and evaluated a number of models using single GPU, DataParallel and DistributedDataParallel training modes and the results are shown in the table below. To reproduce, use the models included in ci/test_integration.sh.
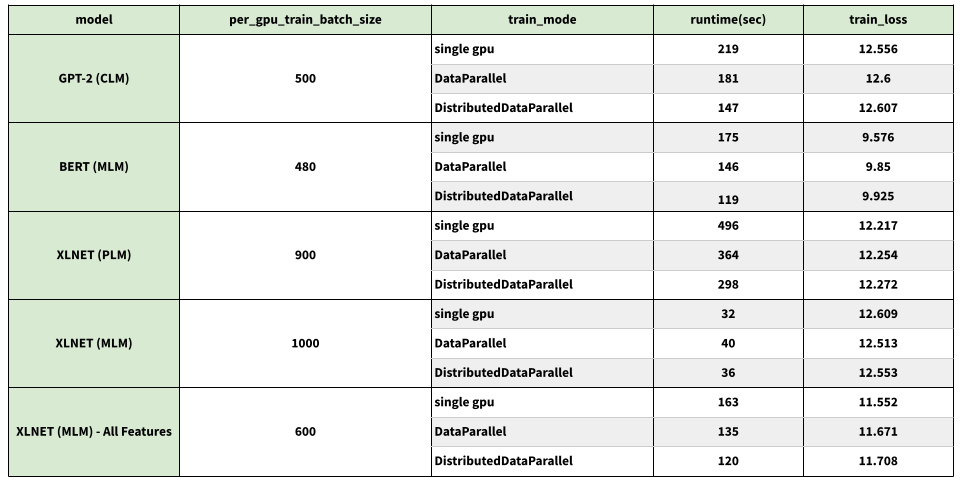
These experiments used a machine with 2 Tesla V100-SXM2-32GB-LS GPUs.
Note: Using Data-Parallel training can impact metrics such at NDCG and recall. Therefore, Users are advised to tune the learning rate for better accuracy.