SparseOperationKit
Sparse Operation Kit (SOK) is a Python package wrapped GPU accelerated operations dedicated for sparse training / inference cases. It is designed to be compatible with common deep learning (DL) frameworks like TensorFlow.
Most of the algorithm implementations in SOK are extracted from HugeCTR. HugeCTR is a GPU-accelerated recommender framework designed to distribute training across multiple GPUs and nodes for Click-Through Rate (CTR) estimation. If you are looking for a very efficient solution for CTR estimation, please see the HugeCTR documentation or our GitHub repository.
Features
Model-Parallelism GPU Embedding Layer
In sparse training / inference scenarios, for instance, CTR estimation, there are vast amounts of parameters which cannot fit into the memory of a single GPU. Many common DL frameworks only offer limited support for model parallelism (MP), because it can complicate using all available GPUs in a cluster to accelerate the whole training process.
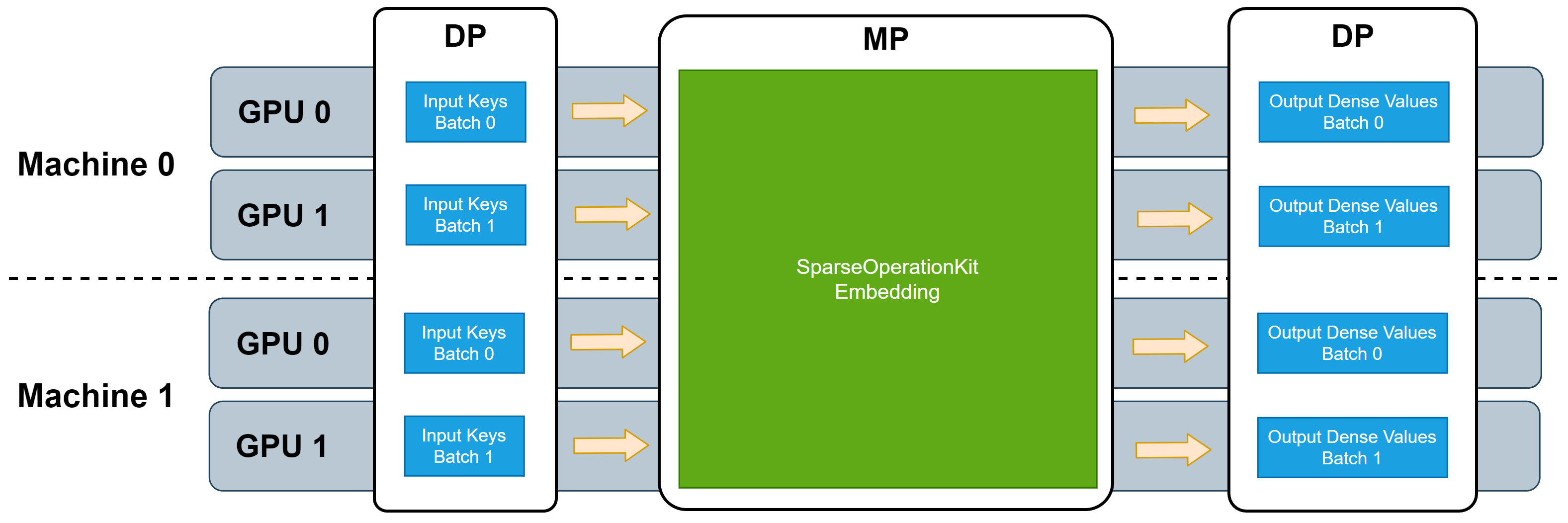
SOK provides broad MP functionality to fully utilize all available GPUs, regardless of whether these GPUs are located in a single machine or multiple machines. Simultaneously, SOK takes advantage of existing data-parallel (DP) capabilities of DL frameworks to accelerate training while minimizing code changes. With SOK embedding layers, you can build a DNN model with mixed MP and DP. MP is used to shard large embedding parameter tables, such that they are distributed among the available GPUs to balance the workload, while DP is used for layers that only consume little GPU resources.
SOK is compatible with DP training provided by common synchronized training frameworks, such as Horovod. Because the input data fed to these embedding layers can take advantage of DP, additional DP from/to MP transformations are needed when SOK is used to scale up your DNN model from single GPU to multiple GPUs. The following picture illustrates the workflow of these embedding layers.
Dynamic Embedding Backend
SOK provides a dynamic embedding table with hash functionality. The features of the dynamic embedding table are as follows:
The memory capacity of the embedding table dynamically grows during training and automatically evicts entries when the limit is reached.
dynamic embedding table can accepts pre-hashed indices.
To achieve these two functions, SOK uses HierarchicalKV as the backend.
HierarchicalKV(Abbreviated as HKV) is a part of NVIDIA Merlin and provides hierarchical key-value storage to meet RecSys requirements.For more detailed information about HKV, you can read documents the HKV repo. Here, SOK lists some key points of HKV for recommendation systems:
HKV supports lookup with pre-hashed indices.
HKV supports setting a capacity limit for the embedding table. When the embedding table reaches its capacity, it can evict embedding vectors using strategies such as LRU and LFU.
HKV can configure the location of the embedding vectors to either GPU global memory or Host memory, take full advantage of the system’s memory.
With these features of HKV, SOK can easily support more flexible lookup of indices, while also expanding the capacity of the embedding table to a large size.
How to use dynamic embedding in SOK, referencing SOK DynamicVariable
How to use dynamic embedding training DLRM, referencing SOK Notebooks
Installation
There are several ways to install this package.
Obtaining SOK And HugeCTR Via Docker
This is the quickest way to get started with SOK.
We provide containers with pre-compiled binaries of the latest HugeCTR and SOK versions(also can manually install SOK into nvcr.io/nvidia/tensorflow series images).
To get started quickly with container on your machine, run the following command:
docker run nvcr.io/nvidia/merlin/merlin-tensorflow:23.11
In production, replace the
latesttag with a specific version. Refer to the Merlin TensorFlow container page on NGC for more information.
Sparse Operation Kit is already installed in the container. You can import the library as shown in the following code block:
import sparse_operation_kit as sok
Installing SOK Via PIP
You can install SOK using the following command:
pip install sparse_operation_kit --no-build-isolation
Installing SOK From Source
You can also build the SOK module from source code. Here are the steps to follow:
Download the source code
$ git clone https://github.com/NVIDIA-Merlin/HugeCTR hugectr
Install to system from python setup install
$ cd hugectr/ $ git submodule update --init --recursive $ cd sparse_operation_kit/ $ python setup.py install
Install to system from cmake
$ cd hugectr/ $ git submodule update --init --recursive $ cd sparse_operation_kit/ $ mkdir build && cd build $ cmake -DSM={your GPU SM version} ../ $ make -j && make install $ cp -r ../sparse_operation_kit {image python dist-packages folder, for example:/usr/local/lib/python3.10/dist-packages/}
Pre-requisites
CUDA Version:>= 11.2
TF2 Version:2.6.0~2.14.0
TF1 Version:1.15
Cmake Version:>= 3.20
GCC Version:>=9.3.0
Build requires: scikit-build>=0.13.1, ninja
Documents
Want to find more about SparseOperationKit? Take a look at the SparseOperationKit documentation!