# Copyright 2023 NVIDIA Corporation. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ================================
# Each user is responsible for checking the content of datasets and the
# applicable licenses and determining if suitable for the intended use.
Building Intelligent Recommender Systems with Merlin#
This notebook is created using the latest stable merlin-tensorflow container.
Overview#
Recommender Systems (RecSys) are the engine of the modern internet and the catalyst for human decisions. Building a recommendation system is challenging because it requires multiple stages (data preprocessing, offline training, item retrieval, filtering, ranking, ordering, etc.) to work together seamlessly and efficiently. The biggest challenges for new practitioners are the lack of understanding around what RecSys look like in the real world, and the gap between examples of simple models and a production-ready end-to-end recommender systems.
The figure below represents a four-stage recommender systems. This is a more complex process than only training a single model and deploying it, and it is much more realistic and closer to what’s happening in the real-world recommender production systems.
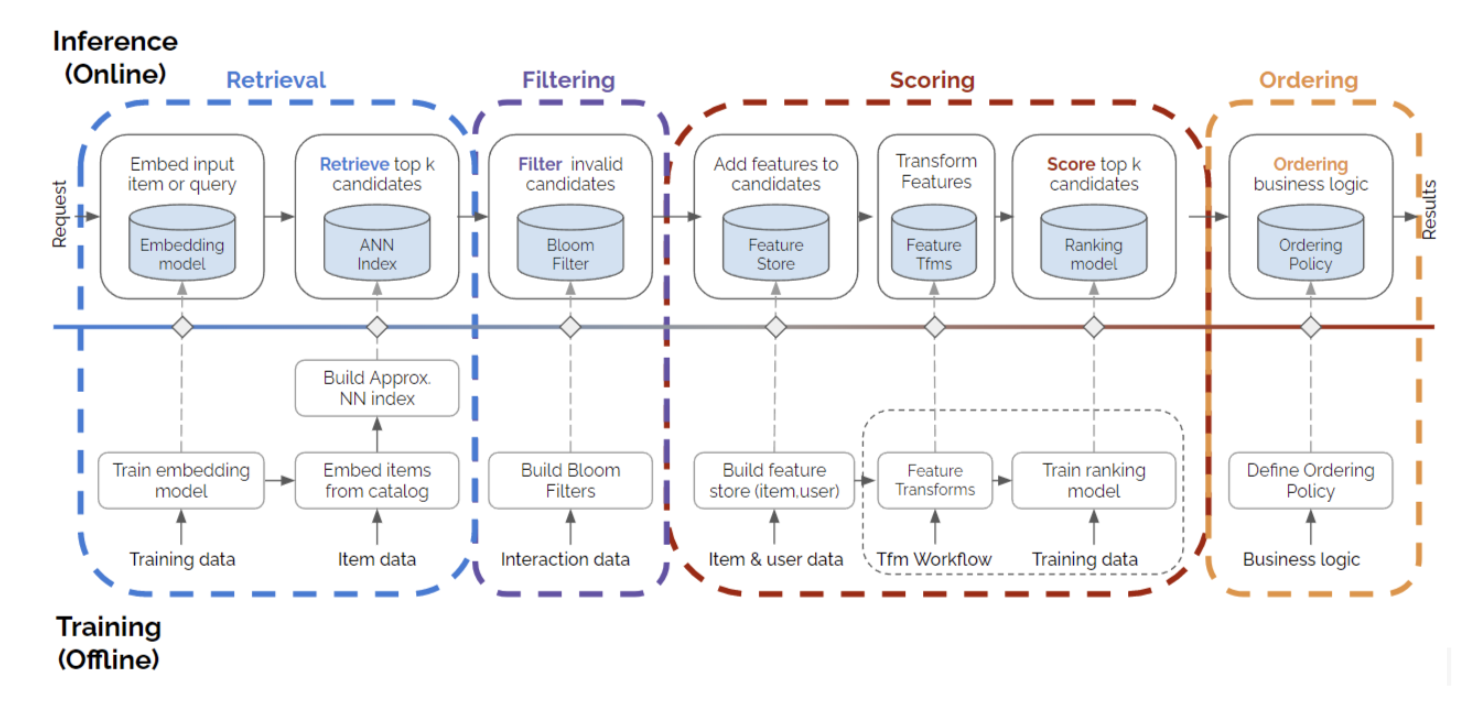
In these series of notebooks, we are going to showcase how we can deploy a four-stage recommender systems using Merlin Systems library easily on Triton Inference Server. Let’s go over the concepts in the figure briefly.
Retrieval: This is the step to narrow down millions of items into thousands of candidates. We are going to train a Two-Tower item retrieval model to retrieve the relevant top-K candidate items.
Filtering: This step is to exclude the already interacted or undesirable items from the candidate items set or to apply business logic rules. Although this is an important step, for this example we skip this step.
Scoring: This is also known as ranking. Here the retrieved and filtered candidate items are being scored. We are going to train a ranking model to be able to use at our scoring step.
Ordering: At this stage, we can order the final set of items that we want to recommend to the user. Here, we’re able to align the output of the model with business needs, constraints, or criteria.
To learn more about the four-stage recommender systems, you can listen to Even Oldridge’s Moving Beyond Recommender Models talk at KDD’21 and read more in this blog post.
Learning objectives#
Understanding four stages of recommender systems
Training retrieval and ranking models with Merlin Models
Setting up feature store and approximate nearest neighbours (ANN) search libraries
Deploying trained models to Triton Inference Server with Merlin Systems
In addition to NVIDIA Merlin libraries and the Triton Inference Server client library, we use two external libraries in these series of examples:
Feast: an end-to-end open source feature store library for machine learning
Faiss: a library for efficient similarity search and clustering of dense vectors
You can find more information about Feast feature store and Faiss libraries in the next notebook.
Import required libraries and functions#
Compatibility:
This notebook is developed and tested using the latest merlin-tensorflow container from the NVIDIA NGC catalog. To find the tag for the most recently-released container, refer to the Merlin TensorFlow page.
# for running this example on GPU, install the following libraries
# %pip install "feast==0.31" faiss-gpu
# for running this example on CPU, uncomment the following lines
# %pip install tensorflow-cpu "feast==0.31" faiss-cpu
# %pip uninstall cudf
import os
import nvtabular as nvt
from nvtabular.ops import Rename, Filter, Dropna, LambdaOp, Categorify, \
TagAsUserFeatures, TagAsUserID, TagAsItemFeatures, TagAsItemID, AddMetadata
from merlin.schema.tags import Tags
from merlin.dag.ops.subgraph import Subgraph
import merlin.models.tf as mm
from merlin.io.dataset import Dataset
from merlin.datasets.ecommerce import transform_aliccp
import tensorflow as tf
# for running this example on CPU, comment out the line below
os.environ["TF_GPU_ALLOCATOR"] = "cuda_malloc_async"
2023-06-29 19:49:32.836544: I tensorflow/core/platform/cpu_feature_guard.cc:194] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: SSE3 SSE4.1 SSE4.2 AVX
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
/usr/local/lib/python3.8/dist-packages/merlin/dtypes/mappings/torch.py:43: UserWarning: PyTorch dtype mappings did not load successfully due to an error: No module named 'torch'
warn(f"PyTorch dtype mappings did not load successfully due to an error: {exc.msg}")
WARNING:tensorflow:Please fix your imports. Module tensorflow.python.training.tracking.data_structures has been moved to tensorflow.python.trackable.data_structures. The old module will be deleted in version 2.11.
[INFO]: sparse_operation_kit is imported
WARNING:tensorflow:Please fix your imports. Module tensorflow.python.training.tracking.base has been moved to tensorflow.python.trackable.base. The old module will be deleted in version 2.11.
[SOK INFO] Import /usr/local/lib/python3.8/dist-packages/merlin_sok-1.1.4-py3.8-linux-x86_64.egg/sparse_operation_kit/lib/libsok_experiment.so
[SOK INFO] Import /usr/local/lib/python3.8/dist-packages/merlin_sok-1.1.4-py3.8-linux-x86_64.egg/sparse_operation_kit/lib/libsok_experiment.so
2023-06-29 19:49:37.094972: I tensorflow/core/platform/cpu_feature_guard.cc:194] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: SSE3 SSE4.1 SSE4.2 AVX
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-06-29 19:49:38.134481: W tensorflow/core/common_runtime/gpu/gpu_bfc_allocator.cc:42] Overriding orig_value setting because the TF_FORCE_GPU_ALLOW_GROWTH environment variable is set. Original config value was 0.
2023-06-29 19:49:38.134526: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1621] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 24576 MB memory: -> device: 0, name: Quadro RTX 8000, pci bus id: 0000:15:00.0, compute capability: 7.5
2023-06-29 19:49:38.135533: W tensorflow/core/common_runtime/gpu/gpu_bfc_allocator.cc:42] Overriding orig_value setting because the TF_FORCE_GPU_ALLOW_GROWTH environment variable is set. Original config value was 0.
2023-06-29 19:49:38.135562: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1621] Created device /job:localhost/replica:0/task:0/device:GPU:1 with 24576 MB memory: -> device: 1, name: Quadro RTX 8000, pci bus id: 0000:2d:00.0, compute capability: 7.5
/usr/local/lib/python3.8/dist-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
[SOK INFO] Initialize finished, communication tool: horovod
# disable INFO and DEBUG logging everywhere
import logging
logging.disable(logging.WARNING)
In this example notebook, we will generate the synthetic train and test datasets mimicking the real Ali-CCP: Alibaba Click and Conversion Prediction dataset to build our recommender system models.
First, we define our input path and feature repo path.
DATA_FOLDER = os.environ.get("DATA_FOLDER", "/workspace/data/")
# set up the base dir for feature store
BASE_DIR = os.environ.get(
"BASE_DIR", "/Merlin/examples/Building-and-deploying-multi-stage-RecSys/"
)
Then, we use generate_data utility function to generate synthetic dataset.
from merlin.datasets.synthetic import generate_data
NUM_ROWS = os.environ.get("NUM_ROWS", 100_000)
train_raw, valid_raw = generate_data("aliccp-raw", int(NUM_ROWS), set_sizes=(0.7, 0.3))
If you would like to use the real ALI-CCP dataset, you can use get_aliccp() function instead. This function takes the raw csv files, and generate parquet files that can be directly fed to NVTabular workflow above.
Set up a feature store with Feast#
Before we move onto the next step, we need to create a Feast feature repository. Feast is an end-to-end open source feature store for machine learning. Feast (Feature Store) is a customizable operational data system that re-uses existing infrastructure to manage and serve machine learning features to real-time models.
We will create the feature repo in the current working directory, which is BASE_DIR for us.
!rm -rf $BASE_DIR/feast_repo
!cd $BASE_DIR && feast init feast_repo
Creating a new Feast repository in /raid/workshared/merlin/examples/Building-and-deploying-multi-stage-RecSys/feast_repo.
You should be seeing a message like Creating a new Feast repository in … printed out above. Now, navigate to the feature_repo folder and remove the demo parquet file created by default, and examples.py file.
feature_repo_path = os.path.join(BASE_DIR, "feast_repo/feature_repo")
if os.path.exists(f"{feature_repo_path}/example_repo.py"):
os.remove(f"{feature_repo_path}/example_repo.py")
if os.path.exists(f"{feature_repo_path}/data/driver_stats.parquet"):
os.remove(f"{feature_repo_path}/data/driver_stats.parquet")
Exporting user and item features#
from merlin.models.utils.dataset import unique_rows_by_features
user_features = (
unique_rows_by_features(train_raw, Tags.USER, Tags.USER_ID)
.compute()
.reset_index(drop=True)
)
We will artificially add datetime and created timestamp columns to our user_features dataframe. This required by Feast to track the user-item features and their creation time and to determine which version to use when we query Feast.
from datetime import datetime
user_features["datetime"] = datetime.now()
user_features["datetime"] = user_features["datetime"].astype("datetime64[ns]")
user_features["created"] = datetime.now()
user_features["created"] = user_features["created"].astype("datetime64[ns]")
user_features[user_features["user_id"] == 7]
| user_id | user_shops | user_profile | user_group | user_gender | user_age | user_consumption_1 | user_consumption_2 | user_is_occupied | user_geography | user_intentions | user_brands | user_categories | datetime | created | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 6 | 7 | 590 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 171 | 293 | 31 | 2023-06-29 19:49:50.300270 | 2023-06-29 19:49:50.303330 |
user_features.to_parquet(
os.path.join(feature_repo_path, "data", "user_features.parquet")
)
item_features = (
unique_rows_by_features(train_raw, Tags.ITEM, Tags.ITEM_ID)
.compute()
.reset_index(drop=True)
)
item_features["datetime"] = datetime.now()
item_features["datetime"] = item_features["datetime"].astype("datetime64[ns]")
item_features["created"] = datetime.now()
item_features["created"] = item_features["created"].astype("datetime64[ns]")
item_features.head()
| item_id | item_category | item_shop | item_brand | item_intention | datetime | created | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 1 | 1 | 1 | 2023-06-29 19:49:50.410715 | 2023-06-29 19:49:50.412307 |
| 1 | 2 | 6 | 412 | 142 | 66 | 2023-06-29 19:49:50.410715 | 2023-06-29 19:49:50.412307 |
| 2 | 3 | 12 | 824 | 284 | 132 | 2023-06-29 19:49:50.410715 | 2023-06-29 19:49:50.412307 |
| 3 | 4 | 18 | 1236 | 426 | 197 | 2023-06-29 19:49:50.410715 | 2023-06-29 19:49:50.412307 |
| 4 | 5 | 24 | 1648 | 568 | 263 | 2023-06-29 19:49:50.410715 | 2023-06-29 19:49:50.412307 |
# save to disk
item_features.to_parquet(
os.path.join(feature_repo_path, "data", "item_features.parquet")
)
Feature Engineering with NVTabular#
output_path = os.path.join(DATA_FOLDER, "processed_nvt")
In the following NVTabular workflow, notice that we apply the Dropna() Operator at the end. We add the Operator to remove rows with missing values in the final DataFrame after the preceding transformations. Although, the synthetic dataset that we generate and use in this notebook does not have null entries, you might have null entries in your user_id and item_id columns in your own custom dataset. Therefore, while applying Dropna() we will not be registering null user_id_raw and item_id_raw values in the feature store, and will be avoiding potential issues that can occur because of any null entries.
user_id_raw = ["user_id"] >> Rename(postfix='_raw') >> LambdaOp(lambda col: col.astype("int32")) >> TagAsUserFeatures()
item_id_raw = ["item_id"] >> Rename(postfix='_raw') >> LambdaOp(lambda col: col.astype("int32")) >> TagAsItemFeatures()
item_cat = Categorify(dtype="int32")
items = (["item_id","item_category", "item_shop", "item_brand"] >> item_cat)
subgraph_item = Subgraph(
"item",
Subgraph("items_cat", items) +
(items["item_id"] >> TagAsItemID()) +
(items["item_category", "item_shop", "item_brand"] >> TagAsItemFeatures())
)
subgraph_user = Subgraph(
"user",
(["user_id"] >> Categorify(dtype="int32") >> TagAsUserID()) +
(
[
"user_shops",
"user_profile",
"user_group",
"user_gender",
"user_age",
"user_consumption_2",
"user_is_occupied",
"user_geography",
"user_intentions",
"user_brands",
"user_categories",
] >> Categorify(dtype="int32") >> TagAsUserFeatures()
)
)
targets = ["click"] >> AddMetadata(tags=[Tags.BINARY_CLASSIFICATION, "target"])
outputs = subgraph_user + subgraph_item + targets
# add dropna op to filter rows with nulls
outputs = outputs >> Dropna()
nvt_wkflow = nvt.Workflow(outputs)
Let’s call transform_aliccp utility function to be able to perform fit and transform steps on the raw dataset applying the operators defined in the NVTabular workflow pipeline below, and also save our workflow model. After fit and transform, the processed parquet files are saved to output_path.
transform_aliccp(
(train_raw, valid_raw), output_path, nvt_workflow=nvt_wkflow, workflow_name="workflow"
)
Training a Retrieval Model with Two-Tower Model#
We start with the offline candidate retrieval stage. We are going to train a Two-Tower model for item retrieval. To learn more about the Two-tower model you can visit 05-Retrieval-Model.ipynb.
Feature Engineering with NVTabular#
We are going to process our raw categorical features by encoding them using Categorify() operator and tag the features with user or item tags in the schema file. To learn more about NVTabular and the schema object visit this example notebook in the Merlin Models repo.
Define a new output path to store the filtered datasets and schema files.
output_path2 = os.path.join(DATA_FOLDER, "processed/retrieval")
train_tt = Dataset(os.path.join(output_path, "train", "*.parquet"))
valid_tt = Dataset(os.path.join(output_path, "valid", "*.parquet"))
We select only positive interaction rows where click==1 in the dataset with Filter() operator.
inputs = train_tt.schema.column_names
outputs = inputs >> Filter(f=lambda df: df["click"] == 1)
nvt_wkflow.fit(train_tt)
nvt_wkflow.transform(train_tt).to_parquet(
output_path=os.path.join(output_path2, "train")
)
nvt_wkflow.transform(valid_tt).to_parquet(
output_path=os.path.join(output_path2, "valid")
)
NVTabular exported the schema file, schema.pbtxt a protobuf text file, of our processed dataset. To learn more about the schema object and schema file you can explore 02-Merlin-Models-and-NVTabular-integration.ipynb notebook.
Read filtered parquet files as Dataset objects.
train_tt = Dataset(os.path.join(output_path2, "train", "*.parquet"), part_size="500MB")
valid_tt = Dataset(os.path.join(output_path2, "valid", "*.parquet"), part_size="500MB")
schema = train_tt.schema.select_by_tag([Tags.ITEM_ID, Tags.USER_ID, Tags.ITEM, Tags.USER]).without(['click'])
train_tt.schema = schema
valid_tt.schema = schema
model_tt = mm.TwoTowerModel(
schema,
query_tower=mm.MLPBlock([128, 64], no_activation_last_layer=True),
samplers=[mm.InBatchSampler()],
embedding_options=mm.EmbeddingOptions(infer_embedding_sizes=True),
)
model_tt.compile(
optimizer="adam",
run_eagerly=False,
loss="categorical_crossentropy",
metrics=[mm.RecallAt(10), mm.NDCGAt(10)],
)
model_tt.fit(train_tt, validation_data=valid_tt, batch_size=1024 * 8, epochs=1)
/usr/local/lib/python3.8/dist-packages/keras/initializers/initializers_v2.py:120: UserWarning: The initializer TruncatedNormal is unseeded and being called multiple times, which will return identical values each time (even if the initializer is unseeded). Please update your code to provide a seed to the initializer, or avoid using the same initalizer instance more than once.
warnings.warn(
9/9 [==============================] - 11s 275ms/step - loss: 8.9538 - recall_at_10: 0.0101 - ndcg_at_10: 0.0067 - regularization_loss: 0.0000e+00 - loss_batch: 8.8711 - val_loss: 8.9179 - val_recall_at_10: 0.0212 - val_ndcg_at_10: 0.0155 - val_regularization_loss: 0.0000e+00 - val_loss_batch: 8.5806
<keras.callbacks.History at 0x7fd4b04139d0>
Exporting query (user) model#
We export the query tower to use it later during the model deployment stage with Merlin Systems.
query_tower = model_tt.retrieval_block.query_block()
query_tower.save(os.path.join(BASE_DIR, "query_tower"))
Training a Ranking Model with DLRM#
Now we will move onto training an offline ranking model. This ranking model will be used for scoring our retrieved items.
Read processed parquet files. We use the schema object to define our model.
# define train and valid dataset objects
train = Dataset(os.path.join(output_path, "train", "*.parquet"), part_size="500MB")
valid = Dataset(os.path.join(output_path, "valid", "*.parquet"), part_size="500MB")
# define schema object
schema = train.schema
target_column = schema.select_by_tag(Tags.TARGET).column_names[0]
target_column
'click'
Deep Learning Recommendation Model (DLRM) architecture is a popular neural network model originally proposed by Facebook in 2019. The model was introduced as a personalization deep learning model that uses embeddings to process sparse features that represent categorical data and a multilayer perceptron (MLP) to process dense features, then interacts these features explicitly using the statistical techniques proposed in here. To learn more about DLRM architetcture please visit Exploring-different-models notebook in the Merlin Models GH repo.
model = mm.DLRMModel(
schema,
embedding_dim=64,
bottom_block=mm.MLPBlock([128, 64]),
top_block=mm.MLPBlock([128, 64, 32]),
prediction_tasks=mm.BinaryClassificationTask(target_column),
)
model.compile(optimizer="adam", run_eagerly=False, metrics=[tf.keras.metrics.AUC()])
model.fit(train, validation_data=valid, batch_size=16 * 1024)
5/5 [==============================] - 5s 305ms/step - loss: 0.6932 - auc: 0.5005 - regularization_loss: 0.0000e+00 - loss_batch: 0.6932 - val_loss: 0.6931 - val_auc: 0.5029 - val_regularization_loss: 0.0000e+00 - val_loss_batch: 0.6931
<keras.callbacks.History at 0x7fd449398a30>
Let’s save our DLRM model to be able to load back at the deployment stage.
model.save(os.path.join(BASE_DIR, "dlrm"))
In the following cells we are going to export the required user and item features files, and save the query (user) tower model and item embeddings to disk. If you want to read more about exporting retrieval models, please visit 05-Retrieval-Model.ipynb notebook in Merlin Models library repo.
Extract and save Item embeddings#
from merlin.systems.dag.ops.tensorflow import PredictTensorflow
from merlin.systems.dag.ops.workflow import TransformWorkflow
workflow = nvt.Workflow(["item_id"] + (['item_id', 'item_brand', 'item_category', 'item_shop'] >> TransformWorkflow(nvt_wkflow.get_subworkflow("item")) >> PredictTensorflow(model_tt.first.item_block())))
item_embeddings = workflow.fit_transform(Dataset(item_features)).to_ddf().compute()
item_embeddings.tail()
| item_id | output_1 | |
|---|---|---|
| 453 | 945 | [0.012117806822061539, -0.02241620607674122, 0... |
| 454 | 948 | [0.012117806822061539, -0.02241620607674122, 0... |
| 455 | 956 | [0.012117806822061539, -0.02241620607674122, 0... |
| 456 | 1437 | [0.012117806822061539, -0.02241620607674122, 0... |
| 457 | 1469 | [0.012117806822061539, -0.02241620607674122, 0... |
# save to disk
item_embeddings.to_parquet(os.path.join(BASE_DIR, "item_embeddings.parquet"))
Create feature definitions#
Now we will create our user and item features definitions in the user_features.py and item_features.py files and save these files in the feature_repo.
file = open(os.path.join(feature_repo_path, "user_features.py"), "w")
file.write(
"""
from datetime import timedelta
from feast import Entity, Field, FeatureView, ValueType
from feast.types import Int32
from feast.infra.offline_stores.file_source import FileSource
user_features = FileSource(
path="{}",
timestamp_field="datetime",
created_timestamp_column="created",
)
user = Entity(name="user_id", value_type=ValueType.INT32, join_keys=["user_id"],)
user_features_view = FeatureView(
name="user_features",
entities=[user],
ttl=timedelta(0),
schema=[
Field(name="user_shops", dtype=Int32),
Field(name="user_profile", dtype=Int32),
Field(name="user_group", dtype=Int32),
Field(name="user_gender", dtype=Int32),
Field(name="user_age", dtype=Int32),
Field(name="user_consumption_2", dtype=Int32),
Field(name="user_is_occupied", dtype=Int32),
Field(name="user_geography", dtype=Int32),
Field(name="user_intentions", dtype=Int32),
Field(name="user_brands", dtype=Int32),
Field(name="user_categories", dtype=Int32),
],
online=True,
source=user_features,
tags=dict(),
)
""".format(
os.path.join(feature_repo_path, "data/", "user_features.parquet")
)
)
file.close()
with open(os.path.join(feature_repo_path, "item_features.py"), "w") as f:
f.write(
"""
from datetime import timedelta
from feast import Entity, Field, FeatureView, ValueType
from feast.types import Int32
from feast.infra.offline_stores.file_source import FileSource
item_features = FileSource(
path="{}",
timestamp_field="datetime",
created_timestamp_column="created",
)
item = Entity(name="item_id", value_type=ValueType.INT32, join_keys=["item_id"],)
item_features_view = FeatureView(
name="item_features",
entities=[item],
ttl=timedelta(0),
schema=[
Field(name="item_category", dtype=Int32),
Field(name="item_shop", dtype=Int32),
Field(name="item_brand", dtype=Int32),
],
online=True,
source=item_features,
tags=dict(),
)
""".format(
os.path.join(feature_repo_path, "data/", "item_features.parquet")
)
)
file.close()
Let’s checkout our Feast feature repository structure.
# install seedir
!pip install seedir
Requirement already satisfied: seedir in /usr/local/lib/python3.8/dist-packages (0.4.2)
Requirement already satisfied: natsort in /usr/local/lib/python3.8/dist-packages (from seedir) (8.4.0)
import seedir as sd
feature_repo_path = os.path.join(BASE_DIR, "feast_repo")
sd.seedir(
feature_repo_path,
style="lines",
itemlimit=10,
depthlimit=3,
exclude_folders=".ipynb_checkpoints",
sort=True,
)
feast_repo/
├─README.md
├─__init__.py
└─feature_repo/
├─__init__.py
├─__pycache__/
│ ├─__init__.cpython-38.pyc
│ ├─example_repo.cpython-38.pyc
│ └─test_workflow.cpython-38.pyc
├─data/
│ ├─item_features.parquet
│ └─user_features.parquet
├─feature_store.yaml
├─item_features.py
├─test_workflow.py
└─user_features.py
Next Steps#
We trained and exported our ranking and retrieval models and NVTabular workflows. In the next step, we will learn how to deploy our trained models into Triton Inference Server (TIS) with Merlin Systems library.
For the next step, move on to the 02-Deploying-multi-stage-Recsys-with-Merlin-Systems.ipynb notebook to deploy our saved models as an ensemble to TIS and obtain prediction results for a given request.