# Copyright 2021 NVIDIA Corporation. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
Getting Started MovieLens: ETL with NVTabular
Overview
NVTabular is a feature engineering and preprocessing library for tabular data designed to quickly and easily manipulate terabyte scale datasets used to train deep learning based recommender systems. It provides a high level abstraction to simplify code and accelerates computation on the GPU using the RAPIDS cuDF library.
Deep Learning models require the input feature in a specific format. Categorical features needs to be continuous integers (0, …, |C|) to use them with an embedding layer. We will use NVTabular to preprocess the categorical features.
One other challenge is multi-hot categorical features. A product can have multiple categories assigned, but the number of categories per product varies. For example, a movie can have one or multiple genres:
Father of the Bride Part II: [Comedy]
Toy Story: [Adventure, Animation, Children, Comedy, Fantasy]
Jumanji: [Adventure, Children, Fantasy]
One strategy is often to use only the first category or the most frequent ones. However, a better strategy is to use all provided categories per datapoint. RAPID cuDF added list support in its latest release v0.16 and NVTabular now supports multi-hot categorical features.
Learning objectives
In this notebook, we learn how to Categorify single-hot and multi-hot categorical input features with NVTabular
Learn NVTabular for using GPU-accelerated ETL (Preprocess and Feature Engineering)
Get familiar with NVTabular’s high-level API
Join two dataframes with
JoinExternaloperatorPreprocess single-hot categorical input features with NVTabular
Preprocess multi-hot categorical input features with NVTabular
Use
LambdaOpfor custom row-wise dataframe manipulations with NVTabular
NVTabular
With the rapid growth in scale of industry datasets, deep learning (DL) recommender models have started to gain advantages over traditional methods by capitalizing on large amounts of training data.
The current challenges for training large-scale recommenders include:
Huge datasets: Commercial recommenders are trained on huge datasets, often several terabytes in scale.
Complex data preprocessing and feature engineering pipelines: Datasets need to be preprocessed and transformed into a form relevant to be used with DL models and frameworks. In addition, feature engineering creates an extensive set of new features from existing ones, requiring multiple iterations to arrive at an optimal solution.
Input bottleneck: Data loading, if not well optimized, can be the slowest part of the training process, leading to under-utilization of high-throughput computing devices such as GPUs.
Extensive repeated experimentation: The whole data engineering, training, and evaluation process is generally repeated many times, requiring significant time and computational resources.
NVTabular is a library for fast tabular data transformation and loading, manipulating terabyte-scale datasets quickly. It provides best practices for feature engineering and preprocessing and a high-level abstraction to simplify code accelerating computation on the GPU using the RAPIDS cuDF library.
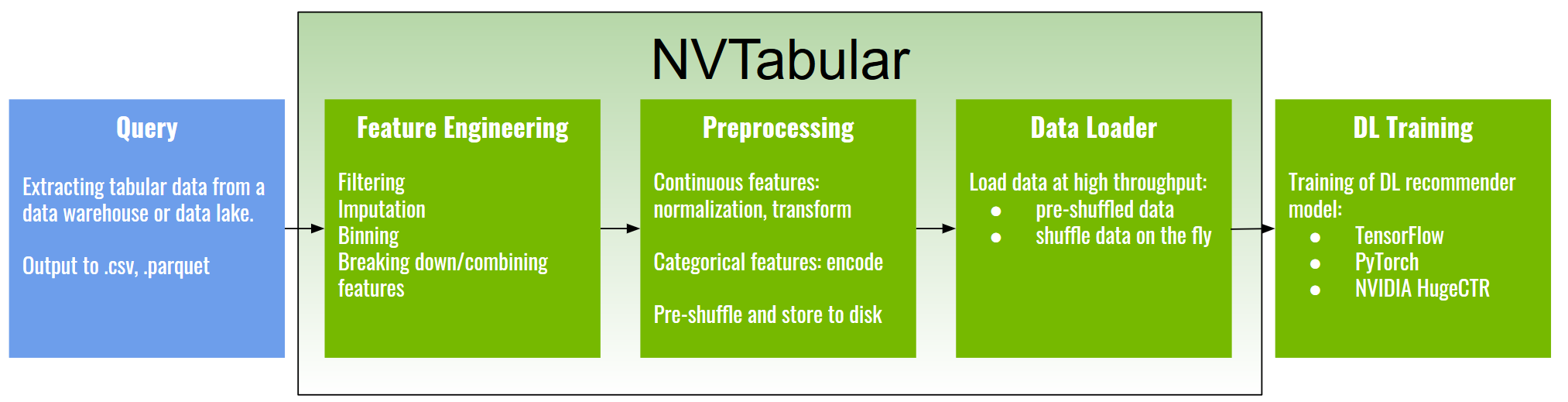
Why use NVTabular?
NVTabular offers multiple advantages to support your Feature Engineering and Preprocessing:
Larger than memory datasets: Your dataset size can be larger than host/GPU memory. NVTabular reads the data from disk and stores the processed files to disk. It will execute your pipeline without exceeding the memory boundaries.
Speed: NVTabular will execute your pipeline on GPU. We experienced 10x-100x speed-up
Easy-to-use: NVTabular implemented common feature engineering and preprocessing operators and provides high-level APIs ready to use
ETL with NVTabular
# External dependencies
import os
import shutil
import numpy as np
import nvtabular as nvt
from os import path
# Get dataframe library - cudf or pandas
from merlin.core.dispatch import get_lib
df_lib = get_lib()
We define our base input directory, containing the data.
INPUT_DATA_DIR = os.environ.get(
"INPUT_DATA_DIR", os.path.expanduser("~/nvt-examples/movielens/data/")
)
movies = df_lib.read_parquet(os.path.join(INPUT_DATA_DIR, "movies_converted.parquet"))
movies.head()
| movieId | genres | |
|---|---|---|
| 0 | 1 | [Adventure, Animation, Children, Comedy, Fantasy] |
| 1 | 2 | [Adventure, Children, Fantasy] |
| 2 | 3 | [Comedy, Romance] |
| 3 | 4 | [Comedy, Drama, Romance] |
| 4 | 5 | [Comedy] |
Defining our Preprocessing Pipeline
The first step is to define the feature engineering and preprocessing pipeline.
NVTabular has already implemented multiple calculations, called ops. An op can be applied to a ColumnGroup from an overloaded >> operator, which in turn returns a new ColumnGroup. A ColumnGroup is a list of column names as text.
Example:
features = [ column_name, ...] >> op1 >> op2 >> ...
This may sounds more complicated as it is. Let’s define our first pipeline for the MovieLens dataset.
Currently, our dataset consists of two separate dataframes. First, we use the JoinExternal operator to left-join the metadata (genres) to our rating dataset.
CATEGORICAL_COLUMNS = ["userId", "movieId"]
LABEL_COLUMNS = ["rating"]
joined = ["userId", "movieId"] >> nvt.ops.JoinExternal(movies, on=["movieId"])
Data pipelines are Directed Acyclic Graphs (DAGs). We can visualize them with graphviz.
joined.graph

Embedding Layers of neural networks require that categorical features are contiguous, incremental Integers: 0, 1, 2, … , |C|-1. We need to ensure that our categorical features fulfill the requirement.
Currently, our genres are a list of Strings. In addition, we should transform the single-hot categorical features userId and movieId, as well.
NVTabular provides the operator Categorify, which provides this functionality with a high-level API out of the box. In NVTabular release v0.3, list support was added for multi-hot categorical features. Both works in the same way with no need for changes.
Next, we will add Categorify for our categorical features (single hot: userId, movieId and multi-hot: genres).
cat_features = joined >> nvt.ops.Categorify()
The ratings are on a scale between 1-5. We want to predict a binary target with 1 for ratings >3 and 0 for ratings <=3. We use the LambdaOp for it.
ratings = nvt.ColumnGroup(["rating"]) >> nvt.ops.LambdaOp(lambda col: (col > 3).astype("int8"))
output = cat_features + ratings
(output).graph

We initialize our NVTabular workflow.
workflow = nvt.Workflow(output)
Running the pipeline
In general, the Ops in our Workflow will require measurements of statistical properties of our data in order to be leveraged. For example, the Normalize op requires measurements of the dataset mean and standard deviation, and the Categorify op requires an accounting of all the categories a particular feature can manifest. However, we frequently need to measure these properties across datasets which are too large to fit into GPU memory (or CPU memory for that matter) at once.
NVTabular solves this by providing the Dataset class, which breaks a set of parquet or csv files into into a collection of cudf.DataFrame chunks that can fit in device memory. The main purpose of this class is to abstract away the raw format of the data, and to allow other NVTabular classes to reliably materialize a dask_cudf.DataFrame collection (and/or collection-based iterator) on demand. Under the hood, the data decomposition corresponds to the construction of a dask_cudf.DataFrame object. By representing our dataset as a lazily-evaluated Dask collection, we can handle the calculation of complex global statistics (and later, can also iterate over the partitions while feeding data into a neural network). part_size defines the size read into GPU-memory at once.
Now instantiate dataset iterators to loop through our dataset (which we couldn’t fit into GPU memory). HugeCTR expect the categorical input columns as int64 and continuous/label columns as float32 We need to enforce the required HugeCTR data types, so we set them in a dictionary and give as an argument when creating our dataset.
dict_dtypes = {}
for col in CATEGORICAL_COLUMNS:
dict_dtypes[col] = np.int64
for col in LABEL_COLUMNS:
dict_dtypes[col] = np.float32
train_dataset = nvt.Dataset([os.path.join(INPUT_DATA_DIR, "train.parquet")])
valid_dataset = nvt.Dataset([os.path.join(INPUT_DATA_DIR, "valid.parquet")])
Now that we have our datasets, we’ll apply our Workflow to them and save the results out to parquet files for fast reading at train time. Similar to the scikit learn API, we collect the statistics of our train dataset with .fit.
%%time
workflow.fit(train_dataset)
CPU times: user 699 ms, sys: 593 ms, total: 1.29 s
Wall time: 1.45 s
<nvtabular.workflow.workflow.Workflow at 0x7f901bd444c0>
We clear our output directories.
# Make sure we have a clean output path
if path.exists(os.path.join(INPUT_DATA_DIR, "train")):
shutil.rmtree(os.path.join(INPUT_DATA_DIR, "train"))
if path.exists(os.path.join(INPUT_DATA_DIR, "valid")):
shutil.rmtree(os.path.join(INPUT_DATA_DIR, "valid"))
We transform our workflow with .transform. We are going to add 'userId', 'movieId', 'genres' columns to _metadata.json, because this json file will be needed for HugeCTR training to obtain the required information from all the rows in each parquet file.
# Add "write_hugectr_keyset=True" to "to_parquet" if using this ETL Notebook for training with HugeCTR
%time
workflow.transform(train_dataset).to_parquet(
output_path=os.path.join(INPUT_DATA_DIR, "train"),
shuffle=nvt.io.Shuffle.PER_PARTITION,
cats=["userId", "movieId", "genres"],
labels=["rating"],
dtypes=dict_dtypes,
)
CPU times: user 3 µs, sys: 1 µs, total: 4 µs
Wall time: 8.82 µs
# Add "write_hugectr_keyset=True" to "to_parquet" if using this ETL Notebook for training with HugeCTR
%time
workflow.transform(valid_dataset).to_parquet(
output_path=os.path.join(INPUT_DATA_DIR, "valid"),
shuffle=False,
cats=["userId", "movieId", "genres"],
labels=["rating"],
dtypes=dict_dtypes,
)
CPU times: user 1 µs, sys: 1 µs, total: 2 µs
Wall time: 4.77 µs
We can take a look in the output dir.
In the next notebooks, we will train a deep learning model. Our training pipeline requires information about the data schema to define the neural network architecture. We will save the NVTabular workflow to disk so that we can restore it in the next notebooks.
workflow.save(os.path.join(INPUT_DATA_DIR, "workflow"))
Checking the pre-processing outputs
We can take a look on the data.
import glob
TRAIN_PATHS = sorted(glob.glob(os.path.join(INPUT_DATA_DIR, "train", "*.parquet")))
VALID_PATHS = sorted(glob.glob(os.path.join(INPUT_DATA_DIR, "valid", "*.parquet")))
TRAIN_PATHS, VALID_PATHS
(['/root/nvt-examples/movielens/data/train/part_0.parquet'],
['/root/nvt-examples/movielens/data/valid/part_0.parquet'])
We can see, that genres are a list of Integers
df = df_lib.read_parquet(TRAIN_PATHS[0])
df.head()
| userId | movieId | genres | rating | |
|---|---|---|---|---|
| 0 | 8439 | 453 | [5, 8, 1] | 1.0 |
| 1 | 76585 | 28 | [11, 7, 4] | 1.0 |
| 2 | 33474 | 1093 | [2, 1] | 1.0 |
| 3 | 2387 | 3754 | [8, 12, 11, 4] | 0.0 |
| 4 | 166 | 559 | [3, 13, 2] | 0.0 |