# Copyright 2021 NVIDIA Corporation. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
Getting Started MovieLens: Training with TensorFlow
Overview
We observed that TensorFlow training pipelines can be slow as the dataloader is a bottleneck. The native dataloader in TensorFlow randomly sample each item from the dataset, which is very slow. The window dataloader in TensorFlow is not much faster. In our experiments, we are able to speed-up existing TensorFlow pipelines by 9x using a highly optimized dataloader.
Applying deep learning models to recommendation systems faces unique challenges in comparison to other domains, such as computer vision and natural language processing. The datasets and common model architectures have unique characteristics, which require custom solutions. Recommendation system datasets have terabytes in size with billion examples but each example is represented by only a few bytes. For example, the Criteo CTR dataset, the largest publicly available dataset, is 1.3TB with 4 billion examples. The model architectures have normally large embedding tables for the users and items, which do not fit on a single GPU. You can read more in our blogpost.
Learning objectives
This notebook explains, how to use the NVTabular dataloader to accelerate TensorFlow training.
Use NVTabular dataloader with TensorFlow Keras model
Leverage multi-hot encoded input features
MovieLens25M
The MovieLens25M is a popular dataset for recommender systems and is used in academic publications. The dataset contains 25M movie ratings for 62,000 movies given by 162,000 users. Many projects use only the user/item/rating information of MovieLens, but the original dataset provides metadata for the movies, as well. For example, which genres a movie has. Although we may not improve state-of-the-art results with our neural network architecture, the purpose of this notebook is to explain how to integrate multi-hot categorical features into a neural network.
NVTabular dataloader for TensorFlow
We’ve identified that the dataloader is one bottleneck in deep learning recommender systems when training pipelines with TensorFlow. The dataloader cannot prepare the next batch fast enough and therefore, the GPU is not fully utilized.
We developed a highly customized tabular dataloader for accelerating existing pipelines in TensorFlow. In our experiments, we see a speed-up by 9x of the same training workflow with NVTabular dataloader. NVTabular dataloader’s features are:
removing bottleneck of item-by-item dataloading
enabling larger than memory dataset by streaming from disk
reading data directly into GPU memory and remove CPU-GPU communication
preparing batch asynchronously in GPU to avoid CPU-GPU communication
supporting commonly used .parquet format
easy integration into existing TensorFlow pipelines by using similar API - works with tf.keras models
More information in our blogpost.
# External dependencies
import os
import glob
import nvtabular as nvt
We define our base input directory, containing the data.
INPUT_DATA_DIR = os.environ.get(
"INPUT_DATA_DIR", os.path.expanduser("~/nvt-examples/movielens/data/")
)
# path to save the models
MODEL_BASE_DIR = os.environ.get("MODEL_BASE_DIR", os.path.expanduser("~/nvt-examples/"))
# avoid numba warnings
from numba import config
config.CUDA_LOW_OCCUPANCY_WARNINGS = 0
Defining Hyperparameters
First, we define the data schema and differentiate between single-hot and multi-hot categorical features. Note, that we do not have any numerical input features.
BATCH_SIZE = 1024 * 32 # Batch Size
CATEGORICAL_COLUMNS = ["movieId", "userId"] # Single-hot
CATEGORICAL_MH_COLUMNS = ["genres"] # Multi-hot
NUMERIC_COLUMNS = []
# Output from ETL-with-NVTabular
TRAIN_PATHS = sorted(glob.glob(os.path.join(INPUT_DATA_DIR, "train", "*.parquet")))
VALID_PATHS = sorted(glob.glob(os.path.join(INPUT_DATA_DIR, "valid", "*.parquet")))
In the previous notebook, we used NVTabular for ETL and stored the workflow to disk. We can load the NVTabular workflow to extract important metadata for our training pipeline.
workflow = nvt.Workflow.load(os.path.join(INPUT_DATA_DIR, "workflow"))
The embedding table shows the cardinality of each categorical variable along with its associated embedding size. Each entry is of the form (cardinality, embedding_size).
EMBEDDING_TABLE_SHAPES, MH_EMBEDDING_TABLE_SHAPES = nvt.ops.get_embedding_sizes(workflow)
EMBEDDING_TABLE_SHAPES.update(MH_EMBEDDING_TABLE_SHAPES)
EMBEDDING_TABLE_SHAPES
{'userId': (162542, 512), 'movieId': (56747, 512), 'genres': (21, 16)}
Initializing NVTabular Dataloader for Tensorflow
We import TensorFlow and some NVTabular TF extensions, such as custom TensorFlow layers supporting multi-hot and the NVTabular TensorFlow data loader.
import os
import time
import tensorflow as tf
from nvtabular.loader.tensorflow import KerasSequenceLoader, KerasSequenceValidater
from nvtabular.framework_utils.tensorflow import layers
First, we take a look on our data loader and how the data is represented as tensors. The NVTabular data loader are initialized as usually and we specify both single-hot and multi-hot categorical features as cat_names. The data loader will automatically recognize the single/multi-hot columns and represent them accordingly.
train_dataset_tf = KerasSequenceLoader(
TRAIN_PATHS, # you could also use a glob pattern
batch_size=BATCH_SIZE,
label_names=["rating"],
cat_names=CATEGORICAL_COLUMNS + CATEGORICAL_MH_COLUMNS,
cont_names=NUMERIC_COLUMNS,
engine="parquet",
shuffle=True,
buffer_size=0.06, # how many batches to load at once
parts_per_chunk=1,
)
valid_dataset_tf = KerasSequenceLoader(
VALID_PATHS, # you could also use a glob pattern
batch_size=BATCH_SIZE,
label_names=["rating"],
cat_names=CATEGORICAL_COLUMNS + CATEGORICAL_MH_COLUMNS,
cont_names=NUMERIC_COLUMNS,
engine="parquet",
shuffle=False,
buffer_size=0.06,
parts_per_chunk=1,
)
/usr/local/lib/python3.8/dist-packages/cudf/core/dataframe.py:1292: UserWarning: The deep parameter is ignored and is only included for pandas compatibility.
warnings.warn(
Let’s generate a batch and take a look on the input features.
We can see, that the single-hot categorical features (userId and movieId) have a shape of (32768, 1), which is the batchsize (as usually).
For the multi-hot categorical feature genres, we receive two Tensors genres__values and genres__nnzs.
genres__values are the actual data, containing the genre IDs. Note that the Tensor has more values than the batch_size. The reason is, that one datapoint in the batch can contain more than one genre (multi-hot).
genres__nnzs are a supporting Tensor, describing how many genres are associated with each datapoint in the batch.
For example,
if the first value in
genres__nnzsis5, then the first 5 values ingenres__valuesare associated with the first datapoint in the batch (movieId/userId).if the second value in
genres__nnzsis2, then the 6th and the 7th values ingenres__valuesare associated with the second datapoint in the batch (continuing after the previous value stopped).if the third value in
genres_nnzsis1, then the 8th value ingenres__valuesare associated with the third datapoint in the batch.and so on
batch = train_dataset_tf.peek()
batch[0]
2022-04-27 22:12:40.128861: I tensorflow/core/platform/cpu_feature_guard.cc:152] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: SSE3 SSE4.1 SSE4.2 AVX
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2022-04-27 22:12:41.479738: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1525] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 16254 MB memory: -> device: 0, name: Quadro GV100, pci bus id: 0000:15:00.0, compute capability: 7.0
2022-04-27 22:12:41.480359: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1525] Created device /job:localhost/replica:0/task:0/device:GPU:1 with 30382 MB memory: -> device: 1, name: Quadro GV100, pci bus id: 0000:2d:00.0, compute capability: 7.0
{'genres': (<tf.Tensor: shape=(88833, 1), dtype=int64, numpy=
array([[ 1],
[ 2],
[ 8],
...,
[ 2],
[ 7],
[17]])>,
<tf.Tensor: shape=(32768, 1), dtype=int32, numpy=
array([[1],
[1],
[3],
...,
[5],
[4],
[4]], dtype=int32)>),
'movieId': <tf.Tensor: shape=(32768, 1), dtype=int64, numpy=
array([[1179],
[ 229],
[1333],
...,
[ 410],
[1153],
[ 460]])>,
'userId': <tf.Tensor: shape=(32768, 1), dtype=int64, numpy=
array([[ 396],
[ 61511],
[ 601],
...,
[134355],
[ 14751],
[ 10238]])>}
We can see that the sum of genres__nnzs is equal to the shape of genres__values.
tf.reduce_sum(batch[0]["genres"][1])
<tf.Tensor: shape=(), dtype=int32, numpy=88833>
As each datapoint can have a different number of genres, it is more efficient to represent the genres as two flat tensors: One with the actual values (genres__values) and one with the length for each datapoint (genres__nnzs).
del batch
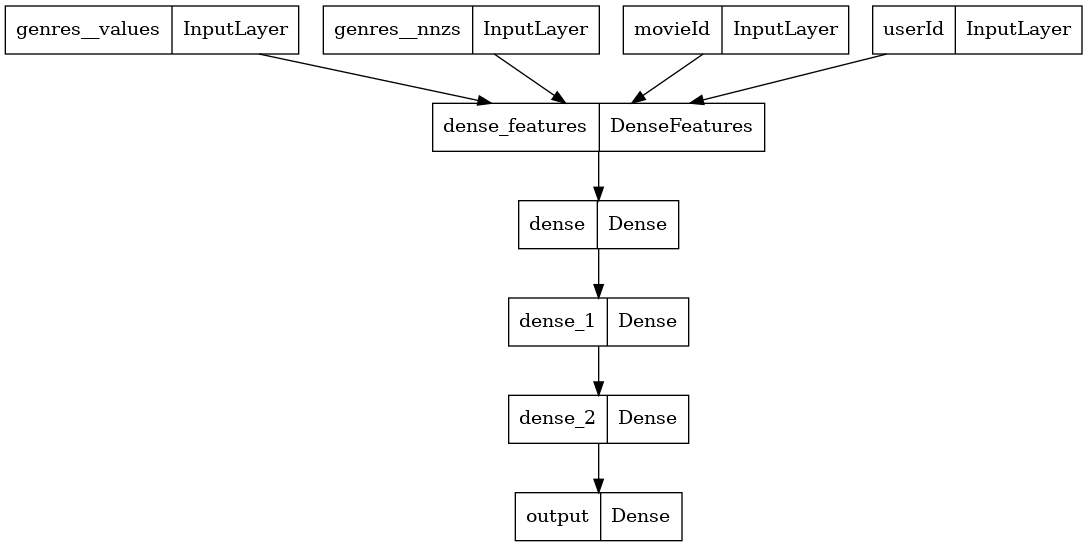
Defining Neural Network Architecture
We will define a common neural network architecture for tabular data.
Single-hot categorical features are fed into an Embedding Layer
Each value of a multi-hot categorical features is fed into an Embedding Layer and the multiple Embedding outputs are combined via averaging
The output of the Embedding Layers are concatenated
The concatenated layers are fed through multiple feed-forward layers (Dense Layers with ReLU activations)
The final output is a single number with sigmoid activation function
First, we will define some dictionary/lists for our network architecture.
inputs = {} # tf.keras.Input placeholders for each feature to be used
emb_layers = [] # output of all embedding layers, which will be concatenated
We create tf.keras.Input tensors for all 4 input features.
for col in CATEGORICAL_COLUMNS:
inputs[col] = tf.keras.Input(name=col, dtype=tf.int64, shape=(1,))
# Note that we need two input tensors for multi-hot categorical features
for col in CATEGORICAL_MH_COLUMNS:
inputs[col] = (tf.keras.Input(name=f"{col}__values", dtype=tf.int64, shape=(1,)),
tf.keras.Input(name=f"{col}__nnzs", dtype=tf.int64, shape=(1,)))
Next, we initialize Embedding Layers with tf.feature_column.embedding_column.
for col in CATEGORICAL_COLUMNS + CATEGORICAL_MH_COLUMNS:
emb_layers.append(
tf.feature_column.embedding_column(
tf.feature_column.categorical_column_with_identity(
col, EMBEDDING_TABLE_SHAPES[col][0]
), # Input dimension (vocab size)
EMBEDDING_TABLE_SHAPES[col][1], # Embedding output dimension
)
)
emb_layers
[EmbeddingColumn(categorical_column=IdentityCategoricalColumn(key='movieId', number_buckets=56747, default_value=None), dimension=512, combiner='mean', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x7fa4cc304460>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, max_norm=None, trainable=True, use_safe_embedding_lookup=True),
EmbeddingColumn(categorical_column=IdentityCategoricalColumn(key='userId', number_buckets=162542, default_value=None), dimension=512, combiner='mean', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x7fa4cc304c10>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, max_norm=None, trainable=True, use_safe_embedding_lookup=True),
EmbeddingColumn(categorical_column=IdentityCategoricalColumn(key='genres', number_buckets=21, default_value=None), dimension=16, combiner='mean', initializer=<tensorflow.python.ops.init_ops.TruncatedNormal object at 0x7fa4cc304a60>, ckpt_to_load_from=None, tensor_name_in_ckpt=None, max_norm=None, trainable=True, use_safe_embedding_lookup=True)]
NVTabular implemented a custom TensorFlow layer layers.DenseFeatures, which takes as an input the different tf.Keras.Input and pre-initialized tf.feature_column and automatically concatenate them into a flat tensor. In the case of multi-hot categorical features, DenseFeatures organizes the inputs __values and __nnzs to define a RaggedTensor and combine them. DenseFeatures can handle numeric inputs, as well, but MovieLens does not provide numerical input features.
emb_layer = layers.DenseFeatures(emb_layers)
x_emb_output = emb_layer(inputs)
x_emb_output
<KerasTensor: shape=(None, 1040) dtype=float32 (created by layer 'dense_features')>
We can see that the output shape of the concatenated layer is equal to the sum of the individual Embedding output dimensions (1040 = 16+512+512).
EMBEDDING_TABLE_SHAPES
{'userId': (162542, 512), 'movieId': (56747, 512), 'genres': (21, 16)}
We add multiple Dense Layers. Finally, we initialize the tf.keras.Model and add the optimizer.
x = tf.keras.layers.Dense(128, activation="relu")(x_emb_output)
x = tf.keras.layers.Dense(128, activation="relu")(x)
x = tf.keras.layers.Dense(128, activation="relu")(x)
x = tf.keras.layers.Dense(1, activation="sigmoid", name="output")(x)
model = tf.keras.Model(inputs=inputs, outputs=x)
model.compile("sgd", "binary_crossentropy")
# You need to install the dependencies
tf.keras.utils.plot_model(model)
Training the deep learning model
We can train our model with model.fit. We need to use a Callback to add the validation dataloader.
validation_callback = KerasSequenceValidater(valid_dataset_tf)
EPOCHS = 1
start = time.time()
history = model.fit(train_dataset_tf, callbacks=[validation_callback], epochs=EPOCHS)
t_final = time.time() - start
total_rows = train_dataset_tf.num_rows_processed + valid_dataset_tf.num_rows_processed
print(
f"run_time: {t_final} - rows: {total_rows * EPOCHS} - epochs: {EPOCHS} - dl_thru: {(EPOCHS * total_rows) / t_final}"
)
609/611 [============================>.] - ETA: 0s - loss: 0.6650{'val_loss': 0.6597499}
611/611 [==============================] - 17s 22ms/step - loss: 0.6650 - val_loss: 0.6597
run_time: 19.14878249168396 - rows: 2292 - epochs: 1 - dl_thru: 119.69429393202323
MODEL_NAME_TF = os.environ.get("MODEL_NAME_TF", "movielens_tf")
MODEL_PATH_TEMP_TF = os.path.join(MODEL_BASE_DIR, MODEL_NAME_TF, "1/model.savedmodel")
model.save(MODEL_PATH_TEMP_TF)
2022-04-27 22:13:04.741886: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
WARNING:absl:Function `_wrapped_model` contains input name(s) movieId, userId with unsupported characters which will be renamed to movieid, userid in the SavedModel.
INFO:tensorflow:Assets written to: /root/nvt-examples/movielens_tf/1/model.savedmodel/assets
INFO:tensorflow:Assets written to: /root/nvt-examples/movielens_tf/1/model.savedmodel/assets
WARNING:absl:<nvtabular.framework_utils.tensorflow.layers.embedding.DenseFeatures object at 0x7fa4cc304370> has the same name 'DenseFeatures' as a built-in Keras object. Consider renaming <class 'nvtabular.framework_utils.tensorflow.layers.embedding.DenseFeatures'> to avoid naming conflicts when loading with `tf.keras.models.load_model`. If renaming is not possible, pass the object in the `custom_objects` parameter of the load function.
Before moving to the next notebook, 04a-Triton-Inference-with-TF.ipynb, we need to generate the Triton Inference Server configurations and save the models in the correct format. We just saved TensorFlow model to disk, and in the previous notebook 02-ETL-with-NVTabular, we saved the NVTabular workflow. Let’s load the workflow.
The TensorFlow input layers expect the input datatype to be int32. Therefore, we need to change the output datatypes to int32 for our NVTabular workflow.
workflow = nvt.Workflow.load(os.path.join(INPUT_DATA_DIR, "workflow"))
MODEL_NAME_ENSEMBLE = os.environ.get("MODEL_NAME_ENSEMBLE", "movielens")
# model path to save the models
MODEL_PATH = os.environ.get("MODEL_PATH", os.path.join(MODEL_BASE_DIR, "models"))
NVTabular provides a function to save the NVTabular workflow, TensorFlow model and Triton Inference Server (IS) config files via export_tensorflow_ensemble. We provide the model, workflow, a model name for ensemble model, path and output column.
# Creates an ensemble triton server model, where
# model: The tensorflow model that should be served
# workflow: The nvtabular workflow used in preprocessing
# name: The base name of the various triton models
from nvtabular.inference.triton import export_tensorflow_ensemble
export_tensorflow_ensemble(model, workflow, MODEL_NAME_ENSEMBLE, MODEL_PATH, ["rating"])
WARNING:absl:Function `_wrapped_model` contains input name(s) movieId, userId with unsupported characters which will be renamed to movieid, userid in the SavedModel.
INFO:tensorflow:Assets written to: /root/nvt-examples/models/movielens_tf/1/model.savedmodel/assets
INFO:tensorflow:Assets written to: /root/nvt-examples/models/movielens_tf/1/model.savedmodel/assets
WARNING:absl:<nvtabular.framework_utils.tensorflow.layers.embedding.DenseFeatures object at 0x7fa4cc304370> has the same name 'DenseFeatures' as a built-in Keras object. Consider renaming <class 'nvtabular.framework_utils.tensorflow.layers.embedding.DenseFeatures'> to avoid naming conflicts when loading with `tf.keras.models.load_model`. If renaming is not possible, pass the object in the `custom_objects` parameter of the load function.
Now, we can move to the next notebook, 04-Triton-Inference-with-TF.ipynb, to send inference request to the Triton IS.