Preprocessing script#
The preprocessing.py is a template script that provides basic preprocessing and feature engineering operations for tabular data, so that they are better represented for neural models. It uses the NVTabular and dask-cudf libraries for GPU accelerated preprocessing.
In this document we describe the provided preprocessing and feature engineering options and the corresponding command line arguments.
Best practices#
In this section we list some best practices on preprocessing and feature engineering for preparing data for neural models.
Dataset#
The typical data to train recommender systems is the log of user interactions on items from a platform like e-commerce, news portal, social network, ad network, streaming media platform, among others. In addition to users interactions. The logged users interaction might contain explicit feedback from users, e.g. like, dislike, rating, or implicit feedback events, e.g. click, comment, add-to-cart, purchase, which might be positive or negative, e.g. items shown to the user and ignored.
Defining the task#
You need to prepare the dataset according to the desired task.
Retrieval - The model objective is to return for a given user the top-k recommended items. In this case, the data can contain only positive interactions as retrieval models are typically trained using negative sampling from other users interactions, not requiring implicit negatives.
Ranking - The model objective is to score the relevance of a target item for a given user. In this case, you have at least one target column that express implicit or explicit your feedback you want to predict. Typically each target will be used by either a binary classification (e.g. predicting binary events like click, --binary_classif_targets) or regression task (e.g. estimating rating, --regression_targets). You can see below an example of the TenRec dataset that is suitable for ranking.
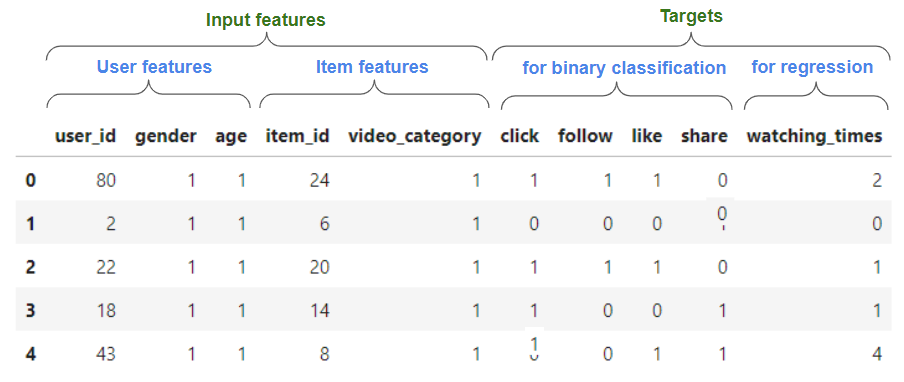
Preprocessing features#
When preparing the data, you need to include features that are relevant for predicting a user interaction, which might include user features that are static (e.g. user id, age, gender), dynamic contextual features (e.g. location, device) and item features (e.g. item id, category, price).
For neural networks there is an important distinction between categorical and continuous features.
Continuous features
Continuous features (--continuous_features) are naturally fed into neural networks, they typically just need need to be normalized to avoid numerical scaling issues. Typical approaches for normalizing continuous features are standardization (Z-scaling) and min-max scaling.
It is important to have a strategy for imputation of missing values (e.g. with a constant float, or some statistic like mean or median), as null (NaN) values are not acceptable as input by neural networks.
Categorical features
Categorical features (--categorical_features) are nominal data, which typically strings or id numbers that don’t have any meaningful order or scaling properties. They are typically categorified / represented as continuous ids, so that when fed to a model they can be represented either as one-hot representation for linear models or embedded for neural networks.
Dealing with high-cardinality data#
Large services might have categorical features with very high cardinality (e.g. order of hundreds of millions or higher), like user id or item id. They typically require a high memory to be stored (e.g. with embedding tables) or processed (e.g. with one-hot encoding). In addition, most of the categorical values are very infrequent, for which it is not possible to learn good embeddings. Thus, your make some modeling choices in order to preprocess those categorical features accordingly. Here are some options:
Keep the original high-cardinality - If you are going use a model with distributed embedding solution, that will support sharding the embedding table across multiple devices(typically GPUs) to avoid going out-of-memory, then you can categorify the features just as you do for low-cardinality ones.
Frequency capping (
--categ_min_freq_capping)- Infrequent values are mapped to 0, forming a cluster of infrequent / cold-start users/items that can be useful for training the model to deal with them.Filtering out infrequent values (
--min_user_freq,--min_item_freq) - You might filter out interactions from infrequent or fresh users or items, which are typically the majority of systems interactions as they typically follow the long-tail distribution.Hashing - An additional option is to hash the categorical values into a number of buckets much lower than the feature cardinality. That way, you introduce collisions as a trade-off for lower final cardinality and memory requirements in the modeling side. This can be in the preprocessing or in the modeling.
Feature Engineering#
Feature engineering allows designing new features from raw data that are can provide useful information to the model with respect to the prediction task.
In this section we list common feature engineering techniques. Most of them are implemented as ops in NVTabular. User defined functions (UDF) can be implemented with Lambda op, which are very useful for example for dealing with temporal and geographic feature engineering.
TIP: This preprocessing script provides just basic feature engineering. For more using those more advanced techniques you can either copy preprocessing.py and change it, or you can create a class inheriting from the PreprocessingRunner class (in preprocessing.py) and override the generate_nvt_features() method to customize the preprocessing workflow with different NVTabular ops.
Continuous features
Smoothing long-tailed distributions of continuous features with Log, so that the range of large numbers is compressed and the range of small numbers is expanded.
Continuous features can be represented as categorical features by either binarization (converting to binary) or binning (converting to multiple categorical or ordinal values). That might be useful to group together values that are similar, e.g., periods of the day, age ranges of users, etc.
Categorical features
Besides contiguous ids, categorical features can be also represented by global statistics of their values, or by statistics conditioned in other columns. Some popular techniques are:
Count encoding - represents the count of a given categorical value across the whole dataset (e.g. count of user past interactions)
Target encoding - represents one statistic of a categorical column conditioned on a target column. One example would be computing the average of click binary target segmented by the item id categorical values, which represents its Click-Through Rate (CTR) or likelihood to be clicked by a random user. Target encoding is a very powerful feature engineering technique, and has been a key for many of our winning solutions for RecSys competitions. You can create target encoded features with this script, by setting the
--target_encoding_featuresand--target_encoding_targetsarguments to define which categorical columns and targets should be used for generating the target encoded features.
Temporal features
Extracting temporal features from timestamps, like day of week, day, month, year, quarter, hour, period of the day, among others.
Compute the “age” of the item or how long the user is active in the system, e.g. by subtracting the interaction timestamp by the timestamp when the user/item were seen for the first time.
Trending features might also be useful: for example, including continuous features that accumulates the user engagement in a specific category of product the last month, quarter, semester.
Geographic features
You can treat Zip codes, cities, states, countries as categorical features
If latitude/longitude are available, you can also compute distances, e.g. the distance between a hotel (item) location and the user location / airport / touristic landmark.
You can also enrich adding features based on external geolocation data (e.g. from census or government).,
Data set splitting#
There are many approaches for splitting (--dataset_split_strategy) train and evaluation data:
random - Examples are randomly assigned to train and eval sets (according to a percentage,
--random_split_eval_perc).random by user - It is like random but stratified by user.Ensures that users have examples in both train and eval sets. This approach doesn’t provide cold-start users on eval set.
temporal - Uses a reference timestamp (
--dataset_split_temporal_timestamp) to split train and eval sets. Typically this is the most realistic approach, as when deployed models will not have access to future information when performing predictions.
Command line arguments#
In this section we describe the command line arguments of the preprocessing script.
The input and format can be CSV, TSV or Parquet, but the latter is recommended for being a columnar format which is faster to preprocess. Output preprocessing format is parquet format.
You can check how to setup the Docker container to run
preprocessing.pyscript with Docker.
Here is an example command line for running preprocessing for the TenRec dataset in our Docker image, which is explained here.
The parameters and their values can be separated by either space or by =.
cd /Merlin/examples/
OUT_DATASET_PATH=/outputs/dataset
python -m quick_start.scripts.preproc.preprocessing --input_data_format=csv --csv_na_values=\\N --data_path /data/QK-video.csv --filter_query="click==1 or (click==0 and follow==0 and like==0 and share==0)" --min_item_freq=30 --min_user_freq=30 --max_user_freq=150 --num_max_rounds_filtering=5 --enable_dask_cuda_cluster --persist_intermediate_files --output_path=$OUT_DATASET_PATH --categorical_features=user_id,item_id,video_category,gender,age --binary_classif_targets=click,follow,like,share --regression_targets=watching_times --to_int32=user_id,item_id --to_int16=watching_times --to_int8=gender,age,video_category,click,follow,like,share --user_id_feature=user_id --item_id_feature=item_id --dataset_split_strategy=random_by_user --random_split_eval_perc=0.2
Inputs#
--data_path
Path to the data
--eval_data_path
Path to eval data, if data was already splitMust have
the same schema as train data (in --data_path).
--predict_data_path
Path to data to be preprocessed for prediction.
This data is expected to have the same input features as
train data but not targets, as this data is used for prediction.
--input_data_format {csv,tsv,parquet}
Input data format
--csv_sep Character separator for CSV files.Default is ','. You
can use 'tab' for tabular separated data, or
--input_data_format tsv
--csv_na_values
String in the original data that should be replaced by
NULL
Outputs#
--output_path
Output path where the preprocessed files will be
savedDefault is ./results/
--output_num_partitions
Number of partitions that result in this number of
output filesDefault is 10.
--persist_intermediate_files
Whether to persist/cache the intermediate
preprocessing files. Enabling this might be necessary
for larger datasets.
Features and targets definition#
--control_features
Columns (comma-separated) that should be kept as is in
the output files. For example,
--control_features=session_id,timestamp
--categorical_features
Columns (comma-sep) with categorical/discrete features
that will encoded/categorified to contiguous ids in
the preprocessing. These tags are tagged as
'categorical' in the schema, so that Merlin Models can
automatically create embedding tables for them.
--continuous_features
Columns (comma-sep) with continuous features that will
be standardized and tagged in the schema as
'continuous', so that the Merlin Models can represent
and combine them with embedding properly.
--continuous_features_fillna
Replaces NULL values with this float. You can also set
it with 'median' for filling nulls with the median
value.
--user_features
Columns (comma-sep) that should be tagged in the
schema as user features. This information might be
useful for modeling later.
--item_features
Columns (comma-sep) that should be tagged in the
schema as item features. This information might be
useful for modeling later, for example, for in-batch
sampling if your data contains only positive examples.
--user_id_feature
Column that contains the user id feature, for tagging
in the schema. This information is used in the
preprocessing if you set --min_user_freq or
--max_user_freq
--item_id_feature
Column that contains the item id feature, for tagging
in the schema. This information is used in the
preprocessing if you set --min_item_freq or
--max_item_freq
--timestamp_feature
Column containing a timestamp or date feature. The
basic preprocessing doesn't extracts date and time
features for it. It is just tagged as 'timestamp' in
the schema and used for splitting train / eval data if
--dataset_split_strategy=temporal is used.
--session_id_feature SESSION_ID_FEATURE
This is just for tagging this feature.
--binary_classif_targets
Columns (comma-sep) that should be tagged in the
schema as binary target. Merlin Models will create a
binary classification head for each of these targets.
--regression_targets
Columns (comma-sep) that should be tagged in the
schema as binary target. Merlin Models will create a
regression head for each of these targets.
Target encoding features#
--target_encoding_features
Columns (comma-sep) with categorical/discrete
features for which target encoding features will be
generated, with the average of the target columns
for each categorical value. The target columns are
defined in --target_encoding_targets. If
--target_encoding_features is not provided but
--target_encoding_targets is, all categorical
features will be used.
--target_encoding_targets
Columns (comma-sep) with target columns that will be
used to compute target encoding features with the
average of the target columns for categorical
features value. The categorical features are defined
in --target_encoding_features. If
--target_encoding_targets is not provided but
--target_encoding_features is, all target columns
will be used.
--target_encoding_kfold
Number of folds for target encoding, in order to
avoid that the current example is considered in the
target encoding feature computation, which could
cause overfitting for infrequent categorical values.
Default is 5
--target_encoding_smoothing
Smoothing factor that is used in the target encoding
computation, as statistics for infrequent
categorical values might be noisy. It makes target
encoding formula = `sum_target_per_categ_value +
(global_target_avg * smooth) / categ_value_count +
smooth`. Default is 10
Data casting and filtering#
--to_int32 Cast these columns (comma-sep) to int32.
--to_int16 Cast these columns (comma-sep) to int16, to save some
memory.
--to_int8 Cast these columns (comma-sep) to int32, to save some
memory.
--to_float32
Cast these columns (comma-sep) to float32
Filtering and frequency capping#
--categ_min_freq_capping
Value used for min frequency capping. If greater than 0, all categorical values which are less frequent than this threshold will be mapped to the null value encoded id.
--min_user_freq
Users with frequency lower than this value are removed
from the dataset (before data splitting).
--max_user_freq
Users with frequency higher than this value are
removed from the dataset (before data splitting).
--min_item_freq
Items with frequency lower than this value are removed
from the dataset (before data splitting).
--max_item_freq
Items with frequency higher than this value are
removed from the dataset (before data splitting).
--num_max_rounds_filtering
Max number of rounds interleaving users and items
frequency filtering. If a small number of rounds is
chosen, some low-frequent users or items might be kept
in the dataset. Default is 5
--filter_query
A filter query condition compatible with dask-cudf
`DataFrame.query()`
Dataset splitting (train and eval sets)#
--dataset_split_strategy {random,random_by_user,temporal}
If None, no data split is performed. If 'random',
samples are assigned randomly to eval set according to
--random_split_eval_perc. If 'random_by_user', users
will have examples in both train and eval set,
according to the proportion specified in
--random_split_eval_perc. If 'temporal', the
--timestamp_feature with
--dataset_split_temporal_timestamp to split eval set
based on time.
--random_split_eval_perc
Percentage of examples to be assigned to eval set. It
is used with --dataset_split_strategy 'random' and
'random_by_user'
--dataset_split_temporal_timestamp
Used when --dataset_split_strategy 'temporal'. It
assigns for eval set all examples where the
--timestamp_feature >= value
CUDA cluster options#
--enable_dask_cuda_cluster
Initializes a LocalCUDACluster for multi-GPU preprocessing.
This is recommended for larger dataset to avoid out-of-memory
errors, when multiple GPUs are available. By default is False.
--dask_cuda_visible_gpu_devices
Ids of GPU devices that should be used for
preprocessing, if any. For example:
--visible_gpu_devices=0,1. Default is None, for using all GPUs
--dask_cuda_gpu_device_spill_frac
Percentage of GPU memory used at which
LocalCUDACluster should spill memory to CPU, before
raising out-of-memory errors. Default is 0.7